What Is Inference in Machine Learning? Explained
Inference in machine learning is when models make predictions from the data they’ve learned from. This is key because it turns a model’s learning into useful insights. These insights are vital for predictive analytics and AI decision-making. Inference uses new data to make predictions. This helps in many areas like healthcare, finance, and tech. By understanding machine learning inference, people can see how important model predictions are. They can also see how these predictions help in making new solutions and decisions.Key Takeaways
- Inference in machine learning refers to the prediction phase following model training.
- Key to predictive analytics and AI decision-making by providing actionable insights.
- Enables real-world applications across various industries including healthcare, finance, and technology.
- Transforms a model’s learning into practical outputs using new, unseen data.
- Understanding inference helps stakeholders recognize the value of model predictions.
Introduction to Machine Learning Inference
Machine learning inference is key to using trained models on new data. It turns theory into action. This is vital for data science, linking model training to real use.Defining Machine Learning Inference
It’s when a trained model makes predictions on new data. Models learn from data during training. Then, inference applies these learnings to new situations. This way, AI in inference helps companies make sense of data, leading to ongoing learning and improvement.Importance of Inference in Machine Learning
Inference is crucial in machine learning. It’s what makes models work in the real world. It turns theory into action, helping in making smart decisions and driving innovation. Plus, it makes sure these insights are used quickly, improving how different industries work.
What Is Inference in Machine Learning?
Inference in machine learning means using a trained model on new data. This helps make predictions or gain insights. It’s where machine learning shows its true value in real life. The model uses what it learned during training to make predictions on new data. This can include predicting trends, finding event likelihoods, or spotting patterns in complex data. Training and inference have different goals. Training learns from past data. Inference uses data interpretation with machine learning to get insights. For example, a trained image model can recognize new images it’s never seen.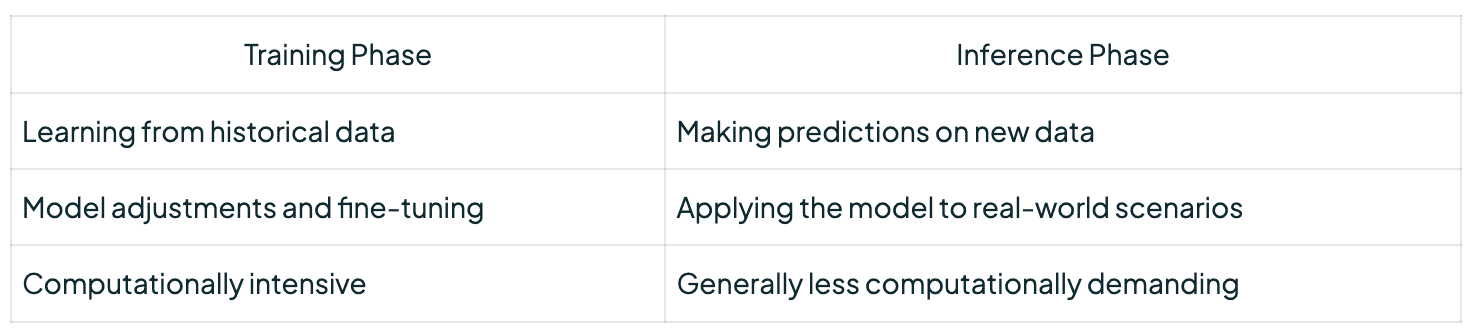
Inference is key to seeing if a model can work well in real life. It checks if the model can make accurate predictions or insights in different situations. So, making inference right is important for using machine learning in the real world. In conclusion, inference in machine learning combines data interpretation with real-time use. It makes sure the models work well in areas like predicting customer behavior, diagnosing diseases, or improving financial forecasts.
The Role of Machine Learning Algorithms in Inference
Machine learning models are key to making systems understand data and make smart choices. They use AI algorithms to look at complex data and find important info.Common Algorithms Used
Important machine learning algorithms are decision trees, neural networks, and support vector machines. Each one helps in different ways during the inference process:- Decision Trees: These create a model that predicts a target variable by learning simple rules from the data.
- Neural Networks: They can handle lots of data and spot patterns. Neural networks are key in deep learning and work well in image and speech recognition.
- Support Vector Machines (SVMs): Great for classifying and predicting, SVMs use a method called the kernel trick to find the best line between groups.
How Algorithms Make Predictions
Machine learning models predict well because of good data and the right algorithm. Here’s how these AI algorithms work:- Data Preparation: Clean, structured data goes into the model.
- Model Training: The algorithm learns from past data to spot patterns and links.
- Validation and Testing: The model’s accuracy is checked on other data.
- Prediction Making: After checking, the model uses its knowledge on new data for predictions.
Supervised Learning and Inference
Supervised learning is a key part of machine learning. It uses labeled data to train models. These models then make decisions based on what they’ve learned from the past.Introduction to Supervised Learning
Algorithms get input-output pairs in supervised learning. This lets the model learn from examples. It’s key for things like recognizing images and filtering spam. The labeled data makes sure the model learns to do specific tasks well. This makes it a strong tool for making predictions.Inference in Supervised Learning Models
Inference is when the trained model predicts outcomes from new data. This is key for many real-world uses. By looking at labeled data, the model spots patterns and relationships. This helps it make better predictions. It improves decision-making in many fields.
Unsupervised Learning and Inference
Unsupervised learning is a key part of machine learning. It finds hidden patterns and structures in data without labels. Unlike supervised learning, it doesn’t need labeled data. This makes it great for clustering and pattern detection tasks. Clustering is a big part of unsupervised learning. It groups data by what they have in common. This is used in many areas like market groups, finding odd data in security, and understanding customer habits in stores. Unsupervised algorithms are also good at reducing data size and finding patterns. Techniques like Principal Component Analysis (PCA) make data easier to see and work with. This is key for showing complex data and making things run faster.| Unsupervised Learning Technique | Description | Application |
|---|---|---|
| Clustering | Groups data points based on similarities | Market Segmentation, Anomaly Detection |
| Dimensionality Reduction | Reduces the number of variables under consideration | Data Visualization, Computational Efficiency |
| Association Rule Learning | Identifies interesting relations between variables | Market Basket Analysis, Recommendation Systems |
Inference Methods in Machine Learning
It’s key to know the main differences in how we make predictions in machine learning. We look at Bayesian and frequentist inference. Each has its own way of working and gives different insights.Bayesian Inference
Bayesian inference uses what we already know and updates it with new info. It makes predictions with probabilistic models. By mixing what we knew before with what we see, we get a new understanding.Frequentist Inference
Frequentist inference looks at how often things happen over time. It doesn’t use what we knew before but finds the best fit for the data. This method is good when we want a clear, objective view.Comparison of Inference Methods
There’s a big debate on which method is better, Bayesian or Frequentist. We look at their good and bad points:| Aspect | Bayesian Inference | Frequentist Inference |
|---|---|---|
| Use of Prior Knowledge | Incorporates prior data | Does not use prior data |
| Interpretation | Probabilistic models for events | Long-run frequencies |
| Flexibility | More flexible with incorporating new data | Less flexible, rigid parameter estimation |
| Complexity | More computationally intensive | Less computationally intensive |
| Application | Useful in dynamic, evolving environments | Best for static, repeated testing scenarios |
Accuracy in Machine Learning Inference
The accuracy of machine learning inference is key to a model’s trustworthiness and success. Model accuracy means how well predictions match real results. It uses various metrics to check how the model does over time. Error rates are a main way to measure how often a model’s guesses are wrong. Low error rates mean the model is very good. High error rates mean it needs work. Precision and recall are also important. They tell us how well a model correctly labels data. Understanding overfitting and underfitting is crucial too. Overfitting means a model learns too much from the training data, doing poorly on new data. Underfitting means a model is too simple and misses important data patterns. The following table shows common performance metrics and what they mean:| Metric | Definition |
|---|---|
| Model Accuracy | The ratio of correctly predicted instances to the total instances |
| Precision | The ratio of true positive results to the sum of true positive and false positive results |
| Recall | The ratio of true positive results to the sum of true positive and false negative results |
| Error Rates | The ratio of the number of incorrect predictions to the total number of predictions |
| F1 Score | The harmonic mean of precision and recall, providing a balance between the two |
Practical Applications of Machine Learning Inference
Machine learning inference is key to real-world success. It helps industries change how they work and make decisions. This section looks at how predictive analytics and AI impact various sectors.Predictive Modeling
Predictive modeling uses machine learning to guess what will happen next with past data. It’s big in finance, predicting stock prices and economic trends. This helps investors and businesses make smart choices to boost profits.Classification and Regression Tasks
Classification and regression are big in machine learning. They help in medical diagnosis, spotting diseases from scans and predicting patient outcomes. This makes diagnoses more accurate and helps in giving patients better care.Real-world Use Cases
Predictive analytics is changing many industries. In retail, it helps manage stock and guess demand. In transport, it makes routes better and cuts down on travel time. These examples show how AI impact boosts efficiency and productivity.| Industry | Application | AI Impact |
|---|---|---|
| Finance | Stock Price Prediction | Improved Investment Strategies |
| Healthcare | Medical Diagnosis | Accurate and Personalized Treatment |
| Retail | Inventory Management | Optimized Stock Levels |
| Transportation | Route Planning | Reduced Commute Times |
Challenges in Machine Learning Inference
Fixing issues in machine learning inference is key for getting good and dependable results. There are three main problems: data quality, model assumptions, and how much it costs to compute.Data Quality Issues
Good data is crucial for machine learning models to work well. Bad data can cause big problems, making models predict wrong. It’s important to clean and check the data carefully to get reliable results.Model Assumptions
Model assumptions are very important in making predictions. If these assumptions are wrong, the results can be way off. It’s important to know the model’s assumptions and make sure they match the data. Updating models often can help avoid these problems.Computational Costs
Computing costs are a big challenge in machine learning inference. As models get more complex, they need more resources to work. You often need advanced methods and strong computers for complex models. Finding a balance between model complexity and cost is key for using machine learning in real life.Improving Machine Learning Inference
Making machine learning better means finding ways to make algorithms work better. By focusing on inference enhancement, we can make predictions more accurate and reliable. A key step is model fine-tuning. This means adjusting the model to fit the data it works with. It often involves making small changes and using methods like grid search to find the best settings. Also, making machine learning efficiency better is crucial. This means picking and creating the right features from data. It helps the model learn easier and perform better. Using cross-validation helps too. This method checks how well the model works on new data. It makes sure the model doesn’t just memorize the training data. This keeps the model reliable and consistent. Finally, keeping an eye on the model and making changes as needed is key. Regular checks help spot problems early and fix them fast. This keeps the model’s performance high.Tools and Libraries for Machine Learning Inference
Choosing the right tools and libraries is key for good machine learning inference. Let’s look at some top ML tools and frameworks. We’ll see how they fit into the machine learning process.Popular Tools and Frameworks
Many ML tools are out there, but some are really strong and versatile:- TensorFlow: TensorFlow is a big open-source library made by Google. It has flexible APIs for complex machine learning and deep learning tasks. It works in many languages and has a big community, making it very popular.
- PyTorch: PyTorch comes from Facebook’s AI Research lab. It’s known for its dynamic computation graph and easy interface. It’s great for both research and production, especially for quick prototyping.
- Scikit-learn: Scikit-learn is a Python library that’s easy to use. It has tools for data mining and analysis, built on NumPy, SciPy, and Matplotlib. It’s a top choice for both beginners and experts.
Integration of Tools in Workflow
It’s important to smoothly add ML tools to your workflow for the best machine learning results. Using these tools with other AI software and platforms can really boost productivity and performance. Here’s how these tools work in a machine learning workflow:| Phase | ML Tool | Description |
|---|---|---|
| Data Preparation | Pandas, NumPy | Doing data tasks before it goes into models. |
| Model Building | TensorFlow, PyTorch, Scikit-learn | Building and training machine learning and deep learning models. |
| Model Evaluation | Scikit-learn, TensorFlow | Checking how well models work with different metrics. |
| Deployment | TensorFlow Serving, ONNX | Putting models into production for real-time use. |
| Monitoring & Maintenance | MLflow, Kubeflow | Tracking experiments, managing models, and keeping an eye on them. |
Conclusion
Inference in machine learning is key to making smart systems work. We looked at what it means and its role in learning. We talked about different ways to do it, like Bayesian and Frequentist methods, and how they work in real life. Getting accurate results from machine learning is crucial for making good decisions. We talked about the challenges like data quality and how to overcome them. Using new tools makes the process easier and fits well with different work flows. The future of AI looks bright as inference gets better. As we improve these methods, the impact on making decisions will grow. By keeping up with these changes, companies can handle the AI future better. This leads to smarter and more efficient systems. If you’re looking to build smarter AI systems or enhance your data-driven decision-making, our expert machine learning engineers can help. Learn more about hiring the right talent here.FAQ
What is inference in machine learning?
Inference in machine learning means using trained models to make predictions. It’s the step after training, where models use new data to produce outputs. This is key for real-world uses in healthcare, finance, and tech.
What defines machine learning inference?
Machine learning inference uses trained models to understand new data. It connects theory to real-world use by giving insights for decisions. This process shows how well models work in real life and helps with new ideas by using data science.
How does machine learning inference differ from training?
Training and inference in machine learning serve different goals. Training uses labeled data for models to learn and predict well. Inference applies these trained models to new data for predictions or insights. Training is learning, and inference is using what we learned.
What common algorithms are used in machine learning inference?
Common algorithms for inference include decision trees, neural networks, and support vector machines. These help find patterns in data and predict outcomes based on what they’ve learned.
How do algorithms make predictions?
Algorithms predict by looking at input data for patterns learned during training. They use this to make predictions, like classifications or regression results. The exact method varies by algorithm.
What is supervised learning in machine learning?
Supervised learning trains models on labeled data. The algorithm learns from input-output pairs to predict on new data. It’s used for tasks like image recognition and spam filtering.
How does inference work in supervised learning models?
In supervised learning, trained models predict on new data using learned patterns. This is used in tasks like classifying emails as spam or predicting house prices.
What is unsupervised learning, and how does its inference work?
Unsupervised learning finds patterns in data without labels. Inference in unsupervised learning spots clusters and structures in data. Tools like K-means clustering and PCA are used here.
What are Bayesian and Frequentist inference methods?
Bayesian inference updates probabilities with new data, while frequentist inference looks at long-term frequencies. Each method has its benefits and is chosen for the task at hand.
How is accuracy measured in machine learning inference?
Accuracy is checked with metrics like precision, recall, F1 score, and accuracy rate. These help see how reliable the model’s predictions are and spot problems like overfitting.
What are some practical applications of machine learning inference?
Machine learning inference is used for forecasting, medical diagnosis, and predicting prices. It’s changing industries by making better decisions and improving efficiency.
What challenges are faced in machine learning inference?
Challenges include data quality issues, wrong model assumptions, and high costs. These can make the inference process less accurate and efficient, needing careful handling and solutions.
How can machine learning inference be improved?
Improve inference by refining algorithms, bettering feature engineering, and using cross-validation. These steps boost accuracy, prevent overfitting, and ensure the model works well on new data.
What tools and libraries are commonly used for machine learning inference?
Tools like TensorFlow, PyTorch, and Scikit-learn are popular. They help with building, training, and deploying models, key for effective machine learning workflows.
Table of Contents
- Introduction to Machine Learning Inference
- What Is Inference in Machine Learning?
- The Role of Machine Learning Algorithms in Inference
- Supervised Learning and Inference
- Unsupervised Learning and Inference
- Inference Methods in Machine Learning
- Accuracy in Machine Learning Inference
- Practical Applications of Machine Learning Inference
- Challenges in Machine Learning Inference
- Improving Machine Learning Inference
- Tools and Libraries for Machine Learning Inference
- Conclusion
- FAQ
Popular
Popular
Recent
Talk to Our Expert
Our journey starts with a 30-min discovery call to explore your project challenges, technical needs and team diversity.

Yaroslav Kuntsevych
co-CEO