

'%3e%3cpath%20d='M0%2040.9959H9.00413V50H0V40.9959ZM0%2040.9959H9.00413V50H0V40.9959ZM0%2027.3306H9.00413V36.3348H0V27.3306ZM0%2013.6653H9.00413V22.6694H0V13.6653ZM0%200H9.00413V9.00408H0V0ZM13.2332%2040.9959H50V50H13.2332V40.9959ZM13.2332%2040.9959H50V50H13.2332V40.9959ZM13.2332%2027.3306H50V36.3348H13.2332V27.3306ZM13.2332%2013.6653H50V22.6694H13.2332V13.6653ZM13.2332%200H50V9.00408H13.2332V0Z'%20fill='%232049d8'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_2_8'%3e%3crect%20width='50'%20height='50'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)




Want to hire Data Pipelines (ETL) developer? Then you should know!
Table of Contents
- Why Hire ETL Developers?
- What They Do and Their Significance
- Advantages and Project Types
- The ETL process
- The “Extract” Phase
- The “Transform” Phase
- The “Load” Phase
- How and where is Data Pipelines (ETL) used?
- TOP 12 Facts about Data Pipelines (ETL)
- What are top Data Pipelines (ETL) instruments and tools?
Why Hire ETL Developers?
ETL (Extract, Transform, Load) developers are specialized engineers skilled in designing and managing data pipelines that extract data from diverse sources, transform it into usable formats, and load it into target systems like data warehouses or databases. Unlike general software developers, ETL developers focus on data engineering, mastering tools like Apache Airflow, Talend, Informatica, or Python-based frameworks such as Pandas and PySpark. With over 5 years of experience, they excel in optimizing data workflows, ensuring data quality, and handling large-scale datasets, making them essential for businesses reliant on data-driven decision-making.What They Do and Their Significance
ETL developers build and maintain data pipelines that integrate disparate data sources—such as APIs, databases (e.g., MySQL, PostgreSQL), or cloud storage (e.g., AWS S3)—into cohesive systems. They leverage tools like Apache NiFi or dbt to transform raw data through cleaning, aggregation, and enrichment, ensuring accuracy and consistency. Their work is critical for enabling real-time analytics, business intelligence, and machine learning by providing structured, reliable data. Their expertise in pipeline orchestration and error handling ensures seamless data flow, reducing processing times by up to 70% compared to manual methods.Advantages and Project Types
Hiring ETL developers offers significant advantages for data-intensive projects. Their proficiency in optimizing data pipelines enhances performance, scalability, and cost-efficiency, outperforming generic developers in handling complex data workflows. They excel in projects like building data warehouses for e-commerce analytics, creating real-time dashboards for fintech platforms, or preparing datasets for machine learning models in healthcare. By automating data integration and ensuring compliance with standards like GDPR, ETL developers deliver reliable solutions that drive insights and operational efficiency across industries.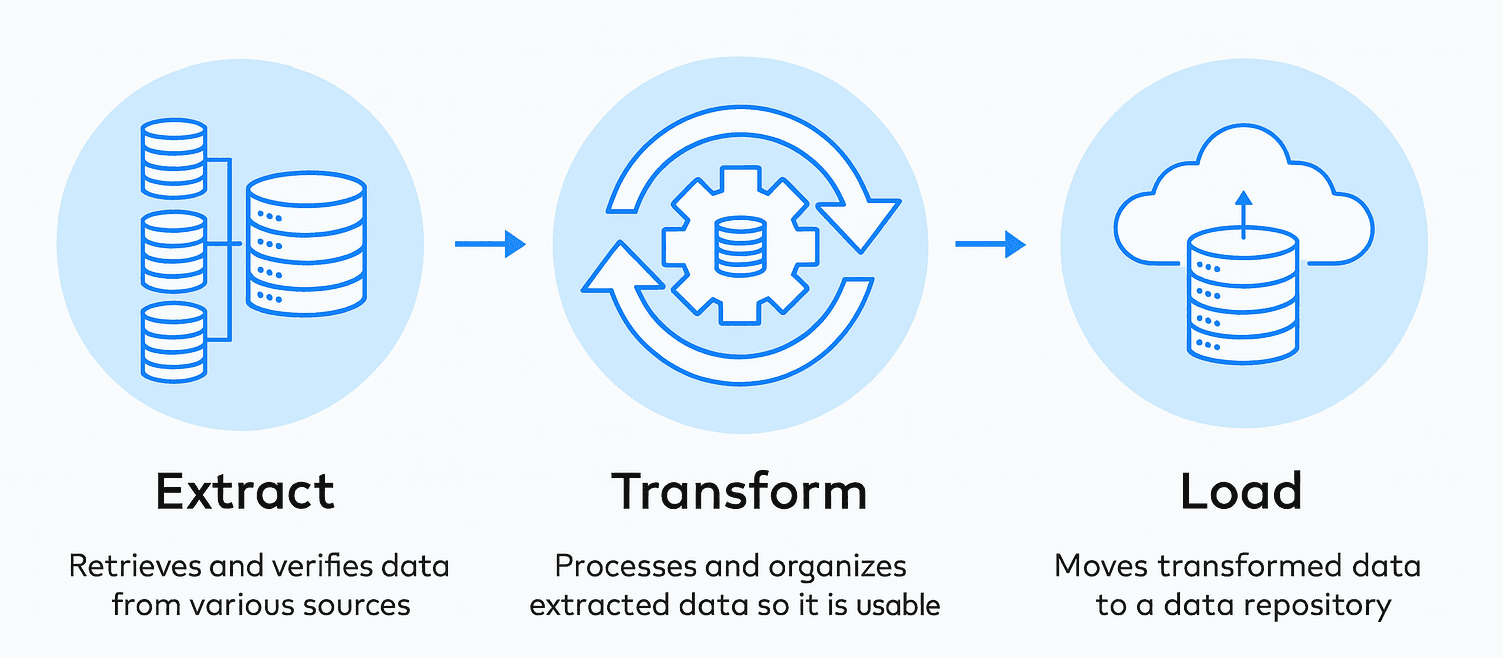
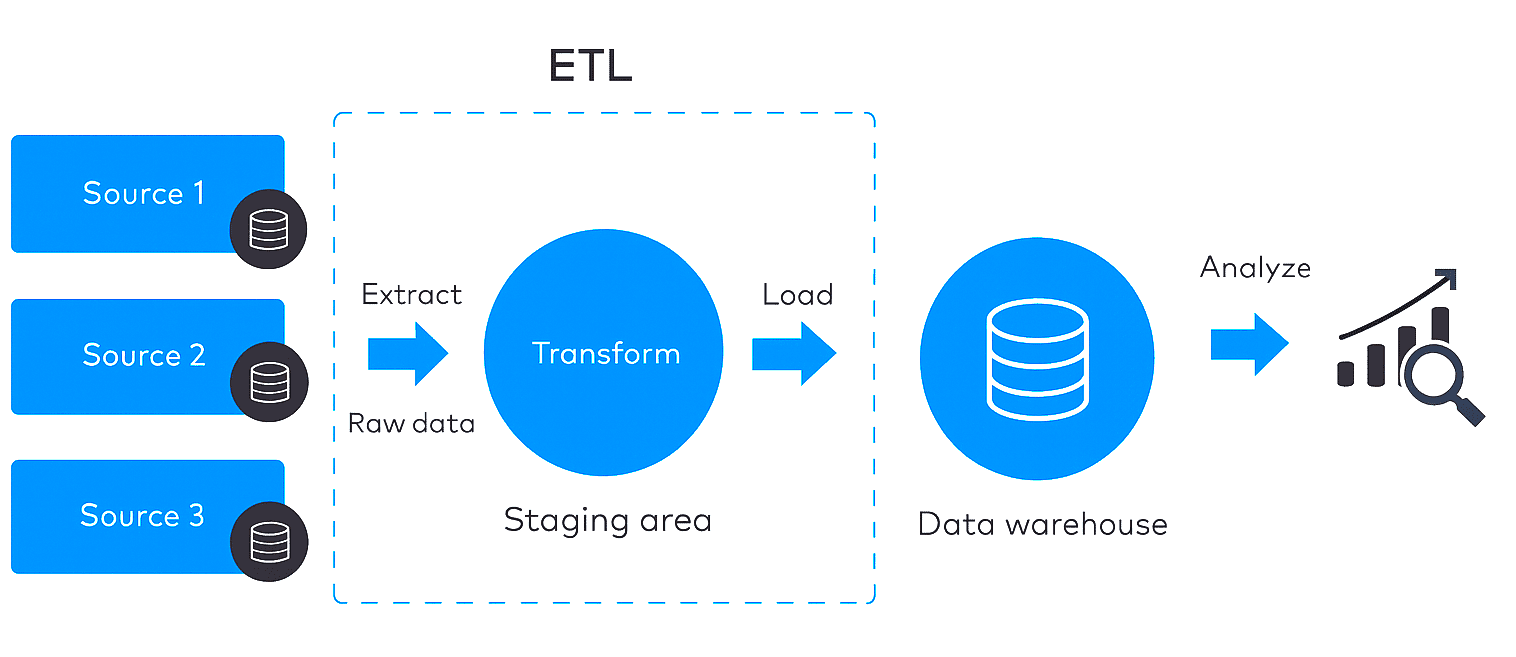
The ETL process
The ETL process does exactly what its name suggests. First, data is extracted from a data source. Then it’s transformed into a relevant format. Finally, the data is loaded into a destination repository, such as a data warehouse or a data mart.The “Extract” Phase
The extraction phase is the first step in the ETL process, where data is retrieved from various source systems. The extraction phase aims to collect data efficiently and reliably from different sources and prepare it for the subsequent transformation and loading stages
Data extraction can involve a wide range of data sources, including:| Data Sources | Challenges |
|---|---|
| Relational databases | Extracting data from databases such as MySQL, Oracle, or SQL Server using SQL queries or database connectors. |
| Files | Data is extracted from flat files, such as CSV, TSV, or XML files, using file readers or parsers. |
| APIs | Retrieve data from web services or APIs using REST or SOAP protocols. |
| CRM and ERP systems | Extracting data from customer relationship management (CRM) systems like Salesforce or enterprise resource planning (ERP) systems like SAP or Oracle. |
| Social media platforms | Collect data from social media APIs like Twitter or Facebook for sentiment analysis or trend monitoring. |
| IoT devices | Extract data from sensors, machines, or other devices for real-time monitoring and analysis. |
The “Transform” Phase
The transformation phase is the heart of the ETL process, where extracted data undergoes a series of modifications and enhancements to ensure its quality, consistency, and compatibility with the target system. Transformation logic is critical to maintaining data integrity and preparing data for analysis and reporting.
The transformation phase is the heart of the ETL process, where extracted data undergoes a series of modifications and enhancements to ensure its quality, consistency, and compatibility with the target system. Transformation logic is critical to maintaining data integrity and preparing data for analysis and reporting.
Data transformation involves various techniques and methods, including:| Techniques and Methods | Challenges |
|---|---|
| Data cleansing | Identifying and correcting data quality issues, such as missing values, duplicates, or inconsistent formats. Data cleansing techniques include data profiling, data validation, and data standardization. |
| Data deduplication | Eliminating duplicate records or merging them into a single representation to ensure data consistency and accuracy. |
| Data validation | Applying business rules and constraints to validate data against predefined criteria, such as data type checks, range checks, or pattern matching. |
| Data enrichment | Enhancing data with additional information from external sources or derived attributes to provide more context and value for analysis. |
| Data aggregation | Summarizing data at different levels of granularity, such as calculating totals, averages, or counts, to support reporting and analysis requirements. |
| Data integration | Combining data from multiple sources into a unified structure, resolving data conflicts, and ensuring data consistency across different systems. |
| Data format conversion | Converting data formats, such as date/time representations or numeric formats, to ensure compatibility with the target system and analysis tools. |
The “Load” Phase
The loading phase is the final step in the ETL process, where the transformed data is loaded into the target system, such as a data warehouse or a data lake. The goal of the loading phase is to efficiently and reliably transfer the processed data into the target system, ensuring data consistency and availability for analysis and reporting.
There are two main strategies for loading data into the target system:
| Strategies | Challenges |
|---|---|
| Full load | In a full load, the entire dataset is loaded into the target system, replacing any existing data. This approach is typically used for initial data loads or when a complete data refresh is required. |
| Incremental load | In an incremental load, only the new or changed data since the last load is appended to the existing data in the target system. This approach is more efficient and reduces the load time compared to a full load, especially for large datasets. |
How and where is Data Pipelines (ETL) used?
| Case Name | Case Description |
|---|---|
| Real-time Analytics | Data pipelines enable the ingestion of large volumes of data from various sources in real-time. This allows organizations to perform real-time analytics, providing valuable insights and enabling timely decision-making. For example, a financial institution can use data pipelines to process real-time market data and perform complex calculations to make informed investment decisions. |
| Data Warehousing | Data pipelines play a crucial role in data warehousing by extracting data from multiple sources, transforming it into a unified format, and loading it into a data warehouse. This enables organizations to consolidate and analyze data from various systems, facilitating better reporting, business intelligence, and data-driven decision-making. |
| Customer Segmentation | Data pipelines can be used to collect and process customer data from different channels, such as websites, mobile apps, and social media platforms. By integrating this data and applying segmentation algorithms, businesses can gain insights into customer behavior, preferences, and demographics, allowing for targeted marketing campaigns and personalized customer experiences. |
| Internet of Things (IoT) Data Processing | Data pipelines are essential in handling the massive amounts of data generated by IoT devices. They enable the collection, transformation, and analysis of IoT data, enabling organizations to monitor and optimize processes, detect anomalies, and create predictive maintenance strategies. For example, a manufacturing plant can use data pipelines to process sensor data from equipment to prevent downtime and improve operational efficiency. |
| Log Analysis | Data pipelines are commonly used in log analysis to process and analyze large volumes of log data generated by systems, applications, and network devices. By extracting relevant information from logs and applying analytics, organizations can identify patterns, troubleshoot issues, and improve system performance. For instance, an e-commerce company can use data pipelines to analyze web server logs to detect and mitigate potential security threats. |
| Fraud Detection | Data pipelines are instrumental in fraud detection by processing and analyzing vast amounts of data in real-time. By integrating data from multiple sources, such as transaction logs, user profiles, and historical patterns, organizations can detect and prevent fraudulent activities promptly. Financial institutions often use data pipelines to identify suspicious transactions, protecting both themselves and their customers. |
| Recommendation Systems | Data pipelines are used in recommendation systems to gather and process user data, such as browsing history, purchase behavior, and preferences. By employing machine learning algorithms, organizations can generate personalized recommendations, enhancing the user experience and driving sales. For example, streaming platforms use data pipelines to analyze user interactions and suggest relevant content. |
| Supply Chain Optimization | Data pipelines are utilized in supply chain optimization to collect and analyze data from various stages of the supply chain, including procurement, manufacturing, logistics, and demand forecasting. By integrating and analyzing this data, organizations can identify inefficiencies, optimize inventory levels, streamline operations, and improve overall supply chain performance. |
| Sentiment Analysis | Data pipelines are employed in sentiment analysis to process and analyze large volumes of textual data, such as customer reviews, social media posts, and customer support interactions. By applying natural language processing techniques, organizations can extract sentiments and opinions, enabling them to understand customer feedback, track brand reputation, and make data-driven decisions to improve products and services. |
TOP 12 Facts about Data Pipelines (ETL)
- Data pipelines, also known as Extract, Transform, Load (ETL) processes, are essential for organizations to ingest, process, and analyze large volumes of data efficiently.
- Data pipelines help ensure data integrity and consistency by transforming and cleaning data from various sources before loading it into a centralized data storage or data warehouse.
- ETL processes typically involve extracting data from multiple sources such as databases, files, APIs, or streaming platforms.
- The extracted data is then transformed to meet specific business requirements, including data cleaning, normalization, aggregation, and enrichment.
- Data pipelines play a crucial role in enabling data integration, allowing organizations to combine and consolidate data from different systems or departments.
- High-quality data pipelines help improve data accuracy, reduce errors, and enhance decision-making processes within an organization.
- ETL processes are often automated to ensure efficiency, scalability, and repeatability, minimizing manual effort and human errors.
- Data pipelines enable real-time or near real-time data processing, allowing organizations to make timely decisions based on the most up-to-date information.
- Robust data pipelines can handle large data volumes and efficiently process data in parallel, ensuring optimal performance and scalability.
- Monitoring and logging mechanisms are crucial components of data pipelines to track data flow, identify issues, and ensure data quality throughout the process.
- Data pipelines can leverage various technologies and tools, such as Apache Kafka, Apache Spark, Apache Airflow, or cloud-based services like AWS Glue or Google Cloud Dataflow.
- Data pipelines are essential in enabling advanced analytics, machine learning, and artificial intelligence applications, as they provide a reliable and consistent flow of data for training and prediction purposes.
What are top Data Pipelines (ETL) instruments and tools?
- Airflow: Airflow is an open-source platform used for orchestrating and scheduling complex data pipelines. It was developed by Airbnb in 2014 and later open-sourced. Airflow allows users to define, schedule, and monitor workflows as directed acyclic graphs (DAGs). It has gained significant popularity due to its scalability, extensibility, and active community support.
- Apache Kafka: Apache Kafka is a distributed streaming platform that is widely used for building real-time data pipelines and streaming applications. It was initially developed by LinkedIn and later open-sourced in 2011. Kafka provides high-throughput, fault-tolerant, and scalable messaging capabilities, making it suitable for handling large volumes of data in real-time.
- Informatica PowerCenter: Informatica PowerCenter is a widely used enterprise data integration platform. It offers a comprehensive set of tools and capabilities for designing, executing, and monitoring data integration workflows. PowerCenter has been in the market for several years and is known for its robustness, scalability, and broad range of connectors and transformations.
- Microsoft SQL Server Integration Services (SSIS): SSIS is a powerful data integration and ETL tool provided by Microsoft as part of its SQL Server suite. It offers a visual development environment for building data integration workflows and supports a wide range of data sources and destinations. SSIS has been widely adopted in the Microsoft ecosystem and is known for its ease of use and integration with other SQL Server components.
- Talend Data Integration: Talend Data Integration is an open-source data integration platform that provides a visual development environment for designing and executing data integration workflows. It offers a wide range of connectors, transformations, and data quality features. Talend has gained popularity due to its user-friendly interface, extensive community support, and rich set of features.
- Google Cloud Dataflow: Google Cloud Dataflow is a fully managed service for building data pipelines and processing large-scale data sets in real-time or batch mode. It offers a unified programming model based on Apache Beam, allowing developers to write data processing logic in multiple programming languages. Dataflow is known for its scalability, fault-tolerance, and integration with other Google Cloud services.
- Amazon Glue: Amazon Glue is a fully managed extract, transform, and load (ETL) service provided by Amazon Web Services (AWS). It offers a serverless environment for building and running data pipelines, along with a visual interface for designing data transformation workflows. Glue supports various data sources and provides features like data cataloging, data cleaning, and job scheduling.
Table of Contents
- Why Hire ETL Developers?
- What They Do and Their Significance
- Advantages and Project Types
- The ETL process
- The “Extract” Phase
- The “Transform” Phase
- The “Load” Phase
- How and where is Data Pipelines (ETL) used?
- TOP 12 Facts about Data Pipelines (ETL)
- What are top Data Pipelines (ETL) instruments and tools?
Talk to Our Expert
Our journey starts with a 30-min discovery call to explore your project challenges, technical needs and team diversity.

Yaroslav Kuntsevych
co-CEO


