Executive Summary
As AI systems scale across sectors like healthcare, manufacturing, and finance, Europe faces a critical challenge: how to orchestrate AI securely across privacy, regulatory, and organizational boundaries. This case study explores a pioneering project that embraces zero-trust architecture, metadata-first orchestration, and mathematical compliance via PDEs. At the heart of this initiative lies a breakthrough: policy-aware orchestration through partial differential equations, allowing AI to run only when privacy, intent, and law align. Upstaff provided specialized AI engineers who tackled the core challenges of federated orchestration, zero-trust metadata, and explainable infrastructure at scale.Dataspace
A dataspace is a federated network designed for secure, decentralized data exchange. It allows organizations to maintain control over their data while enabling interoperability across different platforms and industries. Dataspace enables trusted data sharing in a way that preserves the data sovereignty of participants based on a standard governance framework.- Dataspaces are pivotal in sectors like mobility, healthcare, logistics, and smart cities, where data integration is essential for innovation and efficiency.
- Dataspaces can be purpose- or sector-specific, or cross-sectoral.
Zero-Trust Metadata and Dataspaces
As Europe advances toward a digitally sovereign future, the way we handle data is undergoing a fundamental shift. Traditional architectures such as centralized data lakes, post-hoc compliance checks, monolithic workflows are no longer sufficient. Emerging standards, like the EU AI Act, and GDPR demand real-time governance, privacy-preserving design, and explainability by default. At the frontier of this transformation is a groundbreaking project. Its mission is to reimagine data infrastructure as a policy-aware, zero-trust system built not from pipelines, but from mathematics. At the core of this system are partial differential equations (PDEs) that regulate resource access, data movement, and AI behavior through boundary conditions. This paradigm allows multi-party collaboration without raw data exchange, high-performance computing (HPC) on-demand, with minimal energy footprint, and compliance encoded directly into the infrastructure.How PDE-Orchestrated Infrastructure Differs from Conventional Systems
| Feature | Conventional Cloud AI | PDE-Orchestrated Zero-Trust AI |
| Data Movement | Centralized | Local-only |
| Policy Compliance | Post-hoc | By-construction |
| Resource Usage | Persistent | Ephemeral |
| Governance | Manual | Embedded in PDEs |
| Traceability | Limited | DAG + Policy-bound |
Zero-Trust AI Orchestration Across Privacy and Policy Boundaries
The project’s vision is radical: create a framework where data never moves, but value does.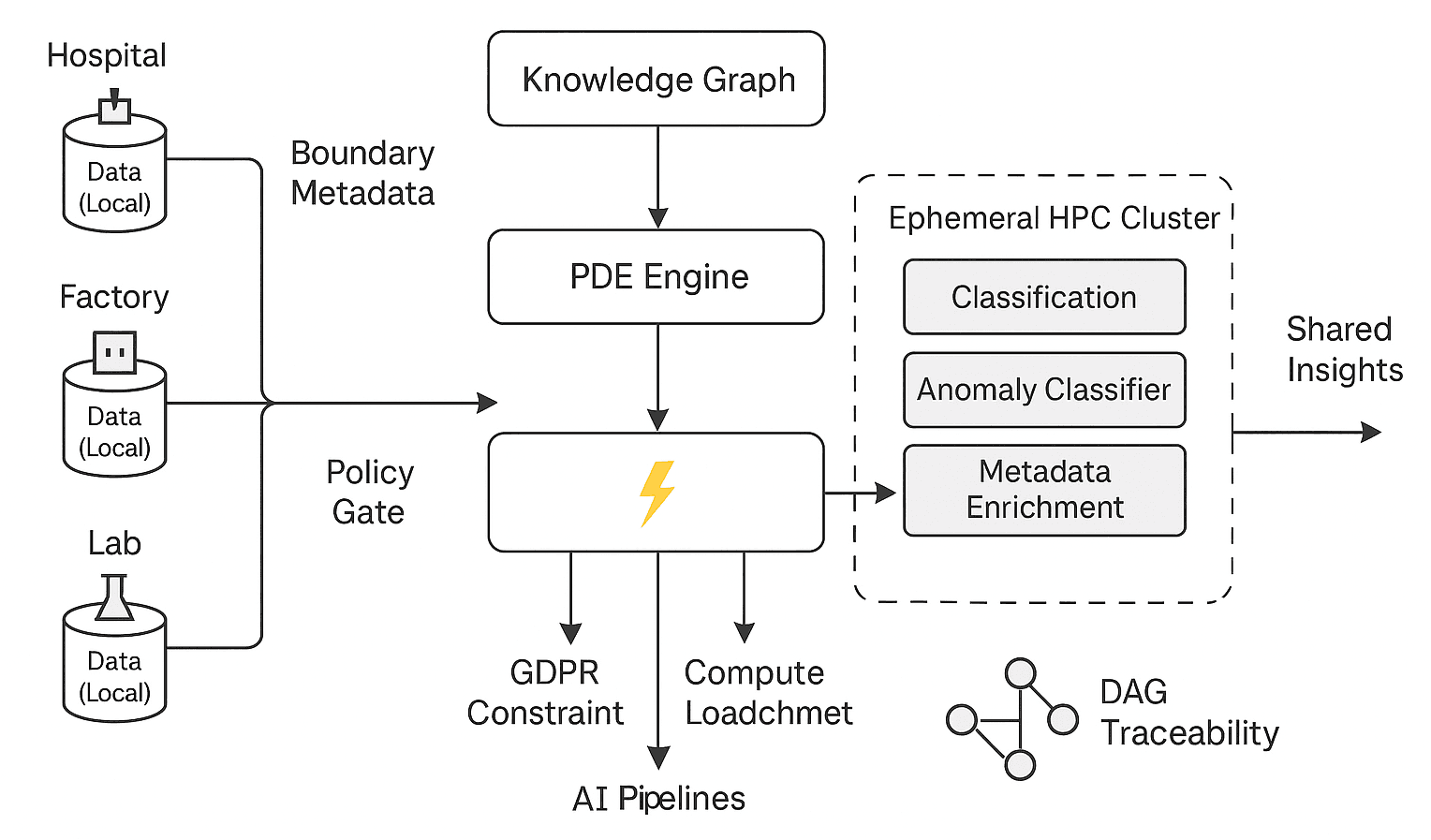 Rather than collecting data into central repositories, each participant in the system, whether in healthcare, manufacturing, or public services, retains full control of their data. A dynamic knowledge graph holds metadata, ontologies, and processing “recipes.” Computation is triggered by PDEs that enforce policy gates (GDPR, ISO, GAMP) as mathematical constraints. When certain boundary conditions are met e.g., a spike in demand or anomaly detection, a short-lived HPC cluster spins up, computes locally, and vanishes.
But to make this vision real, the team needed engineers with a rare mix of skills:
Rather than collecting data into central repositories, each participant in the system, whether in healthcare, manufacturing, or public services, retains full control of their data. A dynamic knowledge graph holds metadata, ontologies, and processing “recipes.” Computation is triggered by PDEs that enforce policy gates (GDPR, ISO, GAMP) as mathematical constraints. When certain boundary conditions are met e.g., a spike in demand or anomaly detection, a short-lived HPC cluster spins up, computes locally, and vanishes.
But to make this vision real, the team needed engineers with a rare mix of skills:- Privacy-preserving machine learning
- Federated AI
- Knowledge graph integration
- Explainable DAG orchestration
- Semantic modeling and metadata processing
- ∂u/∂t + ∇·(α(u)∇u) = f(x, t)– represents AI execution across time and space.
- ∂u/∂t — latency or response time
- α(u) — policy gating / access weights
- f(x, t) — triggers like demand spike or anomaly
- Boundary terms = regulatory or domain-specific constraints, GDPR compliance, semantic gates, user intent.
System Architecture Overview
- Local Data Silos: Hospitals, factories, and labs retain full control of raw data. Nothing is centralized.
- Policy Gate: Applies GDPR, AI Act, and internal policies at the metadata boundary. Invalid flows are filtered before orchestration.
- PDE Engine: The core of the system. It solves boundary-condition equations where each constraint represents a legal, semantic, or resource constraint.
Examples:- A GDPR clause becomes an unsolvable boundary if data leaves its origin.
- A compute budget becomes a conditional activation.
- Knowledge Graph: Stores semantic mappings, policy clauses, domain taxonomies, and orchestration “recipes.” This separates logic from data — enabling fast, ontology-driven decisions.
- Ephemeral HPC Clusters: Resources are spun up only when a PDE solution exists — when policy, readiness, and workload match. These may include:
- Classification models
- Anomaly detectors
- Simulation workloads
- Federated training
- DAG Traceability: Each operation logs its origin: which policy triggered it, which resource was allocated, and which boundary condition was met.
Engineering Stack & Capabilities
| Domain | Contribution | Tools & Methods |
| Federated AI | Built vertical & horizontal pipelines | PySyft, Flower, OpenMined, custom secure aggregation protocols |
| Semantic Modeling | Ontology→PDE mapping | RDF/OWL, Protégé, SPARQL, Neo4j, GraphQL |
| Metadata-First Design | Graph-driven orchestration | GraphQL, custom DAG wrappers, Apache Airflow, Argo Workflows, Prefect, Temporal |
| Explainability & Auditing | Traceable execution lineage | DAG visualizers, metadata provenance tracing, JSON-LD, OpenPolicyAgent logs |
| PDE Compliance Runtime | Mathematical constraint solver | SciPy, JAX, TensorFlow PDE, PyTorch autograd, custom symbolic solvers |
| Infrastructure Engineering | Deployed resilient, policy-aware federated systems across cloud-native and hybrid environments | Amazon Web Services |
Cloud Infrastructure Capability Matrix (AWS-focused)
| Category | AWS Services Listed | Notes |
| Compute & Containerization | ECS, EKS, EC2, Fargate, Lambda | All AWS-native |
| Networking & Security | VPC, PrivateLink, IAM, Security Groups, KMS, Secrets Manager | AWS-specific |
| Storage | S3, EFS, FSx | AWS storage services |
| Serverless Pipelines | Step Functions, EventBridge, DynamoDB Streams | AWS-native serverless tools |
| Data Layer | Neptune, RDS, Aurora, Glue, Athena | All are AWS-managed data services |
| Monitoring & Observability | CloudWatch, X-Ray, OpenTelemetry | OpenTelemetry is cross-cloudst two are AWS |
| Compliance Enforcement | Macie, GuardDuty, Config | All AWS-native compliance/security tools |
PySpark
Flower
OpenMined
RDF/OWL
Protégé
SPARQL
Neo4j
GraphQL
Apache Airflow
Argo workflows
Prefect
Temporal
DAG visualizers
JSON-LD
OPA
SciPy
JAX
TensorFlow
PyTorch
AWS
AWS ECS (Amazon Elastic Container Service)
AWS Elastic Kubernetes Service (EKS)
AWS EC2
AWS Fargate
AWS Lambda
AWS VPC
AWS PrivateLink
AWS IAM
AWS Security Groups
AWS KMS
AWS Secrets Manager
AWS S3
AWS EFS (Amazon Elastic File System)
AWS FSx
AWS Step Functions
AWS EventBridge
AWS DynamoDB
Engineering the Backbone of Federated AI
Among others, Federated AI also allows them to significantly reduce the amount of data they transfer. In fact, some projects managed to reduce their data transfer burden by more than 99% compared to a centralized training model. This is important because moving very large datasets contributes to higher costs, lower performance, and decreased energy efficiency. There are two main approaches to federated AI:- Horizontal federated AI: pulls model weights from the same types of data in every site
- Vertical federated AI: pulls model weights from different types of data in different sites
- Multi-head AI pipelines
Asynchronous pipelines for classification, anomaly detection, and schema interpretation; all integrated into a dynamic metadata fabric. - Semantic-aware orchestration
Knowledge graph outputs to PDE boundary inputs, ensuring compute only runs when policies, semantics, and capacity align. - Zero-trust federation logic
AI workflows to operate without ever touching raw data—only abstracted metadata fragments. - Audit-ready explainability
Directed acyclic graphs (DAGs) to trace each decision back to a semantic label or policy clause, aligning with upcoming EU AI Act requirements.
Results So Far
Though still in active development, the project has made several breakthroughs:- A working alpha prototype of the PDE aggregator with sub-second concurrency response.
- Real-time metadata ingestion and anomaly classification through AI modules.
- Federated learning simulations operating under policy constraints.
- Traceable, explainable orchestration flows through self-documenting DAGs.
Lessons Learned & Engineering Insights
- Math over policies wins: Executable PDEs > static rules
- Metadata is infrastructure: Ontologies replaced scripts
- Compliance must be first-class: Not a feature—an execution condition
- No-code ≠ Low-trust: Engineers must deeply understand the domain and legal semantics
Why This Matters: The Next Wave of AI Infrastructure
 The technical architecture being developed in this project isn’t niche. It’s a preview of where AI and data engineering are headed:
The technical architecture being developed in this project isn’t niche. It’s a preview of where AI and data engineering are headed:- Federated AI in finance and healthcare
- Semantic interoperability across ESG supply chains
- Ephemeral HPC for energy-efficient compute
- Mathematical governance over data flows
Conclusion: Engineering Trustworthy AI at Scale
Real-world AI lives at the intersection of regulation, infrastructure, ethics, and performance. This initiative is a bold attempt to build a system where all those concerns are solved mathematically, structurally, and scalably. This project represents the next step in how industries and governments will govern, scale, and trust AI infrastructure. Compliance isn’t a document, it’s a boundary condition. And orchestration isn’t a workflow, it’s an equation.This wasn’t just another AI project. We were working at the edge of what’s possible in federated orchestration — building systems where compliance, policy, and AI decisions are governed mathematically. It’s the kind of work that pushes you beyond models and into real infrastructure.Upstaff is a platform that connects clients with trusted, pre-vetted AI, Web3, software, and data engineers. As a technology partner, we deliver end-to-end projects or boost teams with pinpoint expertise. W’re proud to have contributed engineers who don’t just build models. They help build the future infrastructure that AI will rely on. If you found this article helpful, feel free to share it and connect with us. We’re always open to new complex, regulated AI infrastructure challenges.
Yaroslav Kuntsevych
CEO @ Upstaff.com
Table of Contents
- Executive Summary
- Dataspace
- Zero-Trust Metadata and Dataspaces
- How PDE-Orchestrated Infrastructure Differs from Conventional Systems
- Zero-Trust AI Orchestration Across Privacy and Policy Boundaries
- System Architecture Overview
- Engineering Stack & Capabilities
- Cloud Infrastructure Capability Matrix (AWS-focused)
- Engineering the Backbone of Federated AI
- Results So Far
- Lessons Learned & Engineering Insights
- Why This Matters: The Next Wave of AI Infrastructure
- Conclusion: Engineering Trustworthy AI at Scale
Popular
Popular
Recent
Talk to Our Expert
Our journey starts with a 30-min discovery call to explore your project challenges, technical needs and team diversity.

Yaroslav Kuntsevych
co-CEO