Introduction
Kafka Streams is a client library for handling real-time data, which is recognized for being simple, efficient, and powerful. Thus it’s gaining popularity within the Apache Foundation projects ecosystem. It helps developers build scalable and fault-tolerant apps and microservices easily. This is thanks to Kafka’s strengths.What is Kafka Streams?
Kafka Streams is a client library for apps and microservices. It uses Kafka clusters for data. It offers simple coding with Streams and Tables. These abstractions make stream processing easier. Developers can write Java and Scala apps. These apps process data in real-time.Why Kafka Streams for Real-Time Data Processing?
Kafka Streams is great for real-time data processing. It’s perfect for monitoring, anomaly detection, or financial transactions. It handles lots of data quickly. It has features that make processing easier. These include scalability, fault tolerance, and easy integration with Kafka and other systems.Core Concepts and Architecture
The Kafka Streams architecture relies on the Kafka platform. Key concepts include:- Streams: They are unbounded sequences of records. Streams are like Kafka topic logs.
- Tables: They store data snapshots. Tables are stateful entities.
- Processing Topology: It’s a graph showing data flow. It shows how data moves from input to output topics.
Setting Up Your Kafka Streams Environment
Setting up a Kafka Streams environment needs some initial steps. Make sure your system meets all requirements and is set up right. This is key for a smooth setup. Here are the necessary steps for a complete setup.Prerequisites and System Requirements
Before you start, make sure you have these basics:- Java Development Kit (JDK) 8 or higher – Kafka Streams uses Java, so you need a JDK.
- Apache Kafka – Check if Kafka is installed and running. Or download it from the Apache Kafka website.
- Maven or Gradle – These tools help manage project dependencies.
Installing Apache Kafka and Kafka Streams Library
With the basics covered, it’s time to install Apache Kafka and set up the Kafka Streams library. Here’s how:- Download Kafka: Get the latest version from the Apache Kafka website. Extract it to your preferred directory.
- Start Kafka Server: Go to the Kafka directory. Start ZooKeeper with
bin/zookeeper-server-start.sh config/zookeeper.properties. Then start the Kafka server withbin/kafka-server-start.sh config/server.properties. - Include Kafka Streams in Your Project: Add the Kafka Streams library to your Maven or Gradle build file. For Maven, add the dependency
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-streams</artifactId><version>{latest_version}</version></dependency>.
Configuration and Setup
After installing Apache Kafka and setting up the library, it’s time for stream processing configuration. This includes important steps:- Specify Essential Properties: Set the application ID, bootstrap servers, and serializers and deserializers for your data’s keys and values in your project’s configuration file.
- Define Topologies: Describe how data is processed through the stream. This includes operations like filtering, mapping, and aggregating.
- Stream Processing Configuration: Add all configurations for stream processing. This includes handling state stores and setting the processing guarantee.
The Architecture of Kafka Streams
Kafka Streams has a strong architecture for efficient and scalable stream processing. Its key components help manage large datasets in real-time. This makes it easy for applications to handle vast amounts of data.Stream Partitions and Parallelism
Stream partitions are key in dividing data for parallel processing. This method helps Kafka Streams scale well and perform better. Each partition works alone, making the system more scalable and reliable.Processing Topology and State Store
The processing topology is like a map for data flow in Kafka Streams. It shows how processors and stateful parts work together. Managing the state store is crucial for storing processing states. This is important for operations like aggregations and joins.Event-Driven Architecture
Kafka Streams uses an event-driven architecture. This means data is processed as it comes in. It’s vital for apps needing quick insights and actions from data streams. Events drive the data flow, making the system fast and efficient.Building Your First Kafka Streams Application
Starting with a Kafka Streams application is exciting. It’s a journey into real-time data processing. This section will guide you through writing your first stream processor, running and testing your application, and debugging common errors. This ensures a solid foundation in stream processor development.Writing Your First Stream Processor
To create a Kafka Streams application, define your stream processor. You can use the high-level DSL (Domain-Specific Language) or the lower-level Processor API. For beginners, the DSL is easier to grasp. It provides a more straightforward way to describe data stream operations. Here’s a basic example:
StreamsBuilder builder = new StreamsBuilder();
KStream source = builder.stream("input-topic");
KStream transformed = source.mapValues(value -> value.toUpperCase());
transformed.to("output-topic");
KafkaStreams streams = new KafkaStreams(builder.build(), props);
streams.start();
Running and Testing Your Application
Before running your Kafka Streams application, ensure it is correctly configured. The TopologyTestDriver allows for efficient application testing and debugging. It enables a simulated processing environment. To test the example stream processor:- Create a
TopologyTestDriverinstance with the stream’s topology and properties. - Pipe input records into the
TopologyTestDriverusing a definedTestInputTopic. - Verify the output using a
TestOutputTopic.
Debugging Common Errors
Debugging in a Kafka Streams application often requires troubleshooting various issues. Common problems include serialization errors, threading model misunderstandings, and incorrect stream processing logic.- Serialization Errors: Ensure that the serializers and deserializers (SerDes) match your data types. Incorrect SerDes configurations often lead to serialization problems.
- Threading Model: Understanding Kafka Streams’ threading model is crucial. Each stream task runs on a separate thread, which can impact your stateful operations.
- Common Errors: Familiarize yourself with typical error messages and their solutions. Kafka documentation and community forums are excellent resources for troubleshooting guidance.
Core APIs in Kafka Streams
The Kafka Streams API has powerful tools for stream processing tasks. It includes the Processor API and the DSL (Domain Specific Language). These APIs are for different levels of complexity and flexibility in stream processing. Processor API: This API lets developers create custom processors. It’s for those who need full control over their stream processing apps. Users can make source, transformation, and sink processors. They can link them to build a custom processing pipeline.“The Processor API is invaluable for applications requiring custom implementations or non-standard processing flows, ensuring high-performance stream processing capabilities.”DSL: The DSL makes stream processing easier with high-level abstractions. Its easy syntax helps with tasks like filtering, transforming, and aggregating data streams. This API is great for quick development and ease of use. Both APIs help build strong, high-performance stream processing apps. The choice between them depends on your specific needs and task complexity.
Stream Processing with Kafka Streams
Kafka Streams has many features for handling data streams in real-time. It works closely with Apache Kafka for smooth operations.Filtering and Transforming Data
Kafka Streams is great at filtering data. It lets you only process data that meets certain criteria. This makes your data cleaner and more focused. Data transformation lets developers change and improve data as it moves through the system. This ensures the data is in the right format before it goes further.Windowing and Aggregations
Windowing functions are key for handling time-based events. They let you work with data in set time frames. This is useful for tracking sessions, monitoring, and analytics. Aggregations help summarize data over these time windows. They give a detailed look at the streaming data. You can get things like counts, sums, and averages.Joining Streams and Tables
Kafka Streams can also join data streams with other data or tables. This makes data processing even more powerful. Join operations combine datasets based on common keys. This helps create complex data relationships. It supports many uses, like recommendation systems and fraud detection.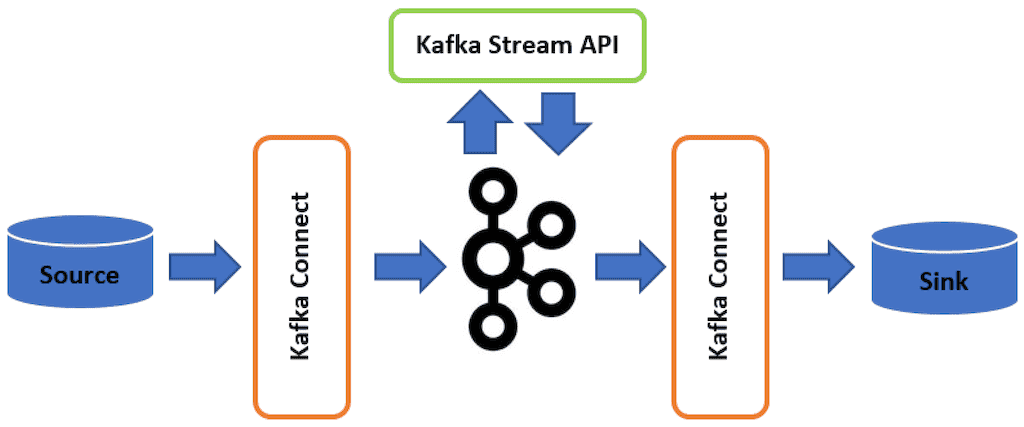
Fault-Tolerant Stream Processing in Kafka
Kafka Streams tackles many challenges in stream processing. It focuses on making the system fault-tolerant. This includes using exactly-once semantics, understanding stateful vs stateless processing, and handling faults.Exactly-Once Semantics
Kafka Streams supports exactly-once semantics. This means each record is processed only once, even if the system fails. It’s key for keeping real-time data processing accurate and reliable.Stateful vs Stateless Processing
Knowing the difference between stateful and stateless processing is important. Stateful stream processing keeps track of state, which can be saved and restored if needed. Stateless processing doesn’t keep state, making it simpler but less powerful for some tasks.Handling Faults and Failures
It’s crucial to have strategies for handling streaming faults. Techniques like replication, log compaction, and change logs help deal with failures. These methods help Kafka Streams apps recover quickly and keep data consistent and reliable.Performance Tuning for Kafka Streams
Getting the best out of Kafka Streams performance is key for handling data in real-time. Tuning performance means using strategies to optimize stream speeds, manage resources well, and keep an eye on performance through benchmarking and monitoring. Each step is important to make sure your Kafka Streams app works well, with little delay and high speed.Optimizing Stream Processing Speed
To speed up streams, you need to tweak consumer and producer settings. This includes adjusting batch sizes, using compression wisely, and setting retention policies. By fine-tuning these settings, you can greatly improve Kafka Streams performance.Resource Management
Managing stream processing resources well means giving enough memory, CPU, and threads. Setting up Java Virtual Machine (JVM) settings and thread pool sizes right helps Kafka Streams handle the workload without slowdowns. Keeping an eye on resource use and scaling up when needed is key to keeping performance high.Benchmarking and Monitoring
It’s vital to regularly benchmark Kafka Streams to know its limits and spot performance problems. Using Kafka’s metrics and tools like Prometheus or Grafana gives deep insights. Always watching performance lets you catch issues fast and keep Kafka Streams performance top-notch.Kafka Streams Use Cases and Real-World Applications
Kafka Streams helps companies build strong stream processing applications. These apps handle big data in real-time. As more businesses rely on data, Kafka Streams use cases have grown in many fields. In finance, real-world Kafka implementations are used for fraud detection. They spot and stop fraud as it happens. In cybersecurity, Kafka Streams helps find unusual patterns and threats fast. E-commerce sites also gain a lot from Kafka Streams. They use it to analyze customer data in real-time. This lets them offer better experiences and keep customers engaged. Plus, Kafka Streams use cases include real-time analytics for quick decisions. Telecom and IoT use Kafka Streams for its speed and growth. It’s great for monitoring network traffic or collecting sensor data. Stream processing applications built on Kafka Streams handle data quickly and accurately. These real-world Kafka implementations show how flexible and powerful Kafka Streams is. It’s key for many stream processing needs. From finance to e-commerce and telecom, Kafka Streams use cases show its value in turning real-time data into insights.Security Considerations for Kafka Streams
When using Kafka Streams, it’s key to add strong security to protect your apps. This keeps your data safe and makes sure only the right people can see it. We’ll cover important security steps like authentication, authorization, and encryption to make your Kafka Streams safer.Securing Your Stream Processing Application
Start by using top security practices for your app. First, make sure data moving around is safe. Use SSL/TLS to encrypt data between parts of your Kafka Streams setup. Also, make sure all communication channels are secure to stop unauthorized access and keep data safe.Authentication and Authorization
Authentication and authorization are big parts of keeping Kafka Streams safe. Authentication checks who’s trying to get into the Kafka cluster. Use SASL or Kerberos for strong identity checks. Authorization lets you control who can see or change data. Use ACLs and RBAC to make sure only the right people can access certain streams and topics.Data Encryption
Encrypting your data is crucial for keeping it safe. Use SSL/TLS to encrypt data moving around. Also, encrypt data stored in Kafka topics or state stores. You can use file encryption or tools like Apache Ranger or AWS KMS. These steps help keep your data safe and sound.
Table of Contents
- Introduction
- Setting Up Your Kafka Streams Environment
- The Architecture of Kafka Streams
- Building Your First Kafka Streams Application
- Core APIs in Kafka Streams
- Stream Processing with Kafka Streams
- Fault-Tolerant Stream Processing in Kafka
- Performance Tuning for Kafka Streams
- Kafka Streams Use Cases and Real-World Applications
- Security Considerations for Kafka Streams
Popular
Popular
Recent
Talk to Our Expert
Our journey starts with a 30-min discovery call to explore your project challenges, technical needs and team diversity.

Yaroslav Kuntsevych
co-CEO