What is a Stream Processing Engine?
Stream processing engines are run-time engines and libraries that allow programmers to write relatively simple code to process data that come in as streams. Such libraries and frameworks empower programmers to process data without having to deal with the details of lower-level stream mechanics.
Direct Acyclic Graph (DAG)
A Direct Acyclic Graph (DAG) is crucial for processing engines, where functions in these engines progress through DAG processes. This concept allows multiple functions to be linked in a specific order, ensuring the process never regresses to an earlier point. See the accompanying graph for a visual representation of DAG in action.
Now that you have some idea of what exactly the stream processing engines are doing, let’s look at two of the most popular processing engines in the world, Flink and Kafka. We will begin by examining the main differences between the two.
Flink Vs. Kafka – Major Differences
If we compare Flink to the Kafka Streams API, the former is what you’d call a data processing framework based on the cluster model, whereas the Kafka Streams API runs as an embeddable library, no clusters required.
The two popular streaming platforms are Apache Flink and Kafka. Flink vs Kafka is similar to the infamous question, Sci-Fi vs Fantasy. While the answer depends on what we are looking for, the fact that there are two distinct approaches makes it challenging. So let us dive into these frameworks to understand Flink vs Kafka.
Flink vs Kafka Streams API: Major Differences
The table below lists the most important differences between Kafka and Flink:
| Apache Flink | Kafka Streams API | |
| Deployment | Flink is a cluster framework, so it handles deployment of your application within a Flink cluster, or using YARN, Mesos or containers (Docker/Kubernetes). | The Streams API is designed so that any standard Java application can embed the Streams API, and as such does not specify any deployment: you can deploy applications with virtually any deployment technology – such as containers (Docker, Kubernetes), resource managers (Mesos, YARN), deployment orchestration (Puppet, Chef, Ansible), or any other in-house tools). |
| Life cycle | User’s stream processing code is deployed and run as a job in the Flink cluster | User’s stream processing code runs inside their application |
| Typically owned by | Data infrastructure or BI team | Line of business team that manages the respective application |
| Coordination | Flink Master (JobManager), part of the streaming program | Leverages the Kafka cluster for coordination, load balancing, and fault-tolerance. |
| Source of continuous data | Kafka, File Systems, other message queues | Strictly Kafka with the Connect API in Kafka serving to address the data into, data out of Kafka problem |
| Sink for results | Kafka, other MQs, file system, analytical database, key/value stores, stream processor state, and other external systems | Kafka, application state, operational database or any external system |
| Bounded and unbounded data streams | Unbounded and Bounded | Unbounded |
| Semantical Guarantees | At least, exactly, once for “everything that internally matters in Flink state”; end-to-end exactly once when selected sources and sinks (eg, Kafka to Flink to HDFS); at least once, “when Kafka is used as a sink, here end-to-end exactly-once guarantee for Kafka likely will happen in the near future. | Exactly-once end-to-end with Kafka |
Flink
The purest streaming engine in this category is Flink from Berlin TU University, which also embraces the lambda architecture, handling batches as a special case of streaming, when data is bounded.
Apache Flink was built from the ground up to be a distributed, high-throughput, stateful, batch and real-time, streaming dataflow engine and framework. It’s designed to be succinct, spreading your stream processing code out from state to state, and parallelising it to take advantage of a cluster. When we needed such a processing engine to support all the real-time data flows and use cases (and there were hundreds of them) at Soul Machines, Apache
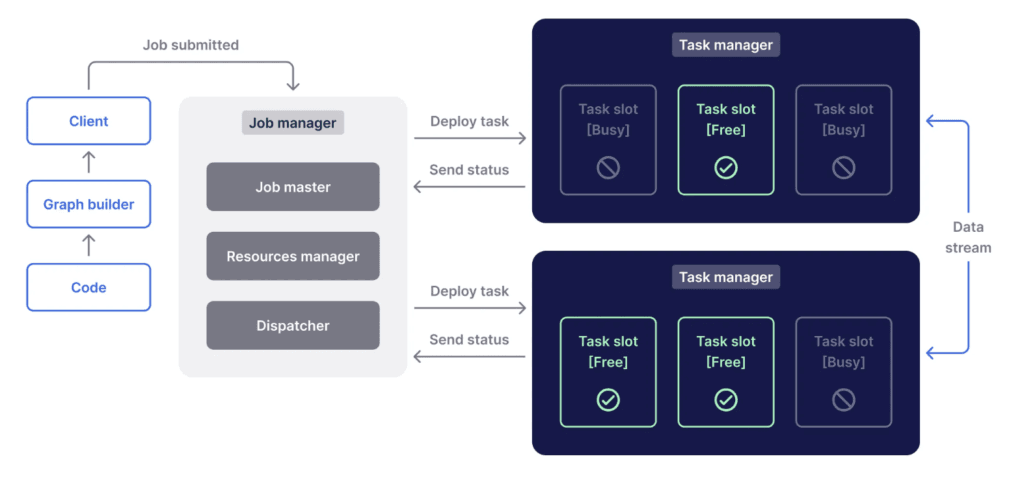
Flink Architecture
Flink was the first open source framework available that could deliver on throughput at this scale (we use Flink for examples up to tens of millions of events per second), sub-second latency at the millisecond resolution (down to as low as 10s of milliseconds), and fault-tolerant results. The streams are executed in isolation on top of an iteration-based cluster model – which can then be deployed using resource managers or simply standalone. The streams can ingest data into streams and even databases, equipped with the corresponding APIs and libraries. These let Flink also function as a batch-processing framework, which itself can run well, even at scale. Most commonly though, Flink is combined with Apache Kafka being the storage layer; however, teams can choose to manage Flink independently to reap the complete benefits of either tool.
By doing this automatically, without requiring specific knowledge of how to apply this tuning, Flink makes it easy to avoid having to get the setting wrong. It was the first true streaming framework. With its event time processing and watermarks advanced features, Flink brings leading-edge stream processing technology to Uber and Alibaba.
Kafka
Kafka Streams API is a lightweight library and stream processing engine for building standard java applications, founded on the functional programming model, and maintaining strong fault tolerance. it can be used as a component of microservices for reactive stateful applications or event-driven systems. It is designed especially for being embedded and integrated into a java application. it is designed on top of its parent technology apache Kafka, and it inherits the power for being distributed and taking advantage of the fault tolerance features provided by Kafka. Whereas you’d typically have to array several servers and configure them as part of a cluster to build an application on top of a messaging system like Kafka, Kafka Streams API is embeddable. This means you can plug it into your existing toolstack without having to build clusters. Your developers can stay in their applications and not worry about how their code gets deployed. And, teams all of a sudden get all the features of Kafka, including failover, scalability and security, at no extra cost.
Industry Example
Further reading on Kafka versus Flink (or technically speaking Flink versus Kafka Streams) will tell you that while Kafka Streams gives you the ability to embed it into any application – even into an application of any weight and complexity – it is not designed to do heavy lifting.
The other major disadvantage at a strict theoretical level is that Kafka doesn’t require a separate cluster to run in, which makes deployment once initiated very easy. In the Apache Flink vs Kafka battle, case studies show that heavy-duty workloads will drive enterprises such as the ride-sharing company Uber to Flink, while companies such as Bouygues Telecom will use Kafka to support real-time analytics and event processing.
In the comparison of Flink vs Kafka Stream, while Kafka Streams is in the leading position for interactive queries (following the deprecation of the feature in Flink due to low community demand), Flink does include an application mode for easy microservices development, although many users still prefer to use Kafka Streams.
Kafka Streams vs. Flink: Key Differences
To select the right candidate stream processing system, assess your options on multiple axes – deployment, usability, architecture, performance (thruput and latency) and more.
Architecture and Deployment
The Apache Kafka uses a message broker system based on a publish/subscribe architecture in which components are chained together. The API, Kafka Streams (also using a broker-based distributed computing solution), using the broker stores data in a very small embedded database. The Kafka Streams API’s library can be added to an existing application, or one can deploy Kafka over clusters as a standalone, using containers, resource managers, or deployment automation tools such as Puppet.
Core of Flink: a distributed computing framework Grouped into one job, the application is deployed either as a standalone cluster or distributed over YARN, Mesos or other container services, such as Docker or Kubernetes. A dedicated master node is required for co-ordination, though that adds to the complexity of Flink.
Complexity and Accessibility
Ease of use hinges on who is using it. Kafka Streams and Flink are used by the developers and the data analysts that need them, and so their complexity is relative.
In contrast to R, Kafka Streams is relatively easy both to get started with and to manage over time, as far as a Java or Scala developer is concerned. It’s easy to deploy standard Java and Scala programs with Kafka Streams, and Kafka Streams is generally usable out of the box. You don’t have to instrument any cluster manager before you can get started. So, there’s far less complexity in Kafka Streams. If you’re not a developer, this is also quite a steep learning curve.
Flink’s UI is easy to use, and its intuitive documentation makes it easier and faster to get going. However, Flink itself runs in the cluster, which can be a bit of a black box. Usually, this is also configured by the infrastructure team. This can reduce some of the setup work for developers and data scientists. Because of its flexibility, Flink can readily be configured to meet different data sources, and comes with native support for numerous third-party data sources.
Other Notable Differences
Some other considerations when looking at Kafka Streams vs. Flink:
- Stream type: Kafka Streams only supports unbounded streams (ie, streams with a start but no defined end) versus Flink, which supports both bounded (ie, defined start and end) and unbounded streams.
- Maintenance: Since Flink is a system installed at the infrastructure level, its management is generally handled by an infrastructure team, not by developers (who manage the application that incorporates Kafka Streams).
- Data sources: while Flink is able to generate output from multiple sources (external files and sinks or other message queues), Kafka Streams are tied to Kafka topics as the source. Both can use different types of data for sink/output.
Kafka Streams vs. Flink Use Cases
You can implement stream processing among your user-facing applications, as well as in-between such apps and your data analytics apps.
The approach of using either Kafka Streams or Apache Flink is similar, and the main difference between the two comes down to a matter of location: with Flink, the stream processing logic resides in a cluster; with Kafka Streams, it resides inside each microservice.
That is, being in different worlds, they can be used together. Kafka Stream is great for microservices and ‘internet of things’ applications. You can build an application on its API that can help microservices or applications to take real-time decisions. It is not so good at analytics, which is where Flink comes in. Big companies such as Uber and Alibaba are deploying it in their environments. You can process data quickly, and make decisions on that basis, faster.
When evaluating Kafka Streams vs. Flink, make sure to:
- Just double-check your use case and your tech stack.
If you’re trying to do something relatively simple, you probably don’t need a sophisticated stream framework – like a simple event-based alerting system using Kafka Streams, versus trying to manage several data types across several different sources using Flink. - Look into tomorrow.
Maybe your team has, at most, just a few features that need stream processing. Big deal, right? But what about the future? If you plan to start using more events, more aggregation and more streams, Flink just offers an advanced streaming framework. Once you’ve invested in and already implemented a technology, it’s usually hard to change later. It’s also expensive.
Final Thoughts

So there are grounds for comparing Kafka Streams to Flink, even though we are not really comparing apples to apples. The result of this architecture difference is that Kafka and Flink do not live in the same part of the company. For many users, this makes Kafka Streams and Flink complementary, systems to be used in tandem as they provide a best-of-both-worlds scenario.
Kafka Streams contains all the benefits of Kafka (latency, throughput, scale, reliability), and a minimalistic API that can be used to create applications in real time.
Flink can be deployed into an existing cluster, and it will grant teams the same latency, throughput, checkpoints and other operational comforts that they have in stores and industrial/financial applications, as well as the visual UI.