

'%3e%3cpath%20d='M0%2040.9959H9.00413V50H0V40.9959ZM0%2040.9959H9.00413V50H0V40.9959ZM0%2027.3306H9.00413V36.3348H0V27.3306ZM0%2013.6653H9.00413V22.6694H0V13.6653ZM0%200H9.00413V9.00408H0V0ZM13.2332%2040.9959H50V50H13.2332V40.9959ZM13.2332%2040.9959H50V50H13.2332V40.9959ZM13.2332%2027.3306H50V36.3348H13.2332V27.3306ZM13.2332%2013.6653H50V22.6694H13.2332V13.6653ZM13.2332%200H50V9.00408H13.2332V0Z'%20fill='%232049d8'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_2_8'%3e%3crect%20width='50'%20height='50'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)








Want to hire AWS Redshift developer? Then you should know!
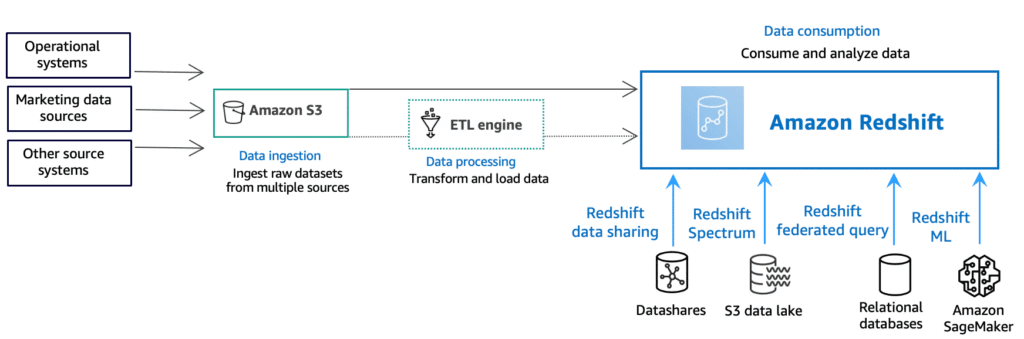
Amazon Redshift Serverless lets you access and analyze data without all of the configurations of a provisioned data warehouse.

TOP 11 Tech facts and history of creation and versions about AWS Redshift Development
- AWS Redshift, a fully managed data warehousing service, was introduced by Amazon Web Services in 2012.
- The development of Redshift was led by Anurag Gupta, who aimed to provide a cost-effective and scalable solution for analyzing large datasets.
- Redshift is based on a columnar storage architecture, which enables faster query performance and reduces I/O overhead.
- It uses massively parallel processing (MPP) to distribute and parallelize data across multiple nodes, allowing for high scalability and efficient data processing.
- The first version of Redshift utilized hard disk drives (HDD) for storage, but later versions introduced support for solid-state drives (SSD) to further improve performance.
- In 2017, Amazon introduced the Redshift Spectrum feature, which enables users to query data directly from Amazon S3, eliminating the need to load data into Redshift clusters.
- In 2019, AWS launched the RA3 node type for Redshift, which combines SSD storage with compute power, providing enhanced performance and scalability.
- Redshift offers a range of data compression techniques, such as run-length encoding and delta encoding, to optimize storage and reduce costs.
- Amazon Redshift integrates with various AWS services, including AWS Glue for data cataloging and AWS Identity and Access Management (IAM) for secure access control.
- Redshift supports a variety of data ingestion methods, including bulk data loading, streaming data ingestion through Amazon Kinesis, and data replication from other databases.
- Since its inception, Redshift has gained popularity among organizations of all sizes, including startups, enterprises, and government agencies, due to its scalability, cost-effectiveness, and ease of use.
How and where is AWS Redshift used?
| Case Name | Case Description |
|---|---|
| Data Warehousing | AWS Redshift is widely used for data warehousing purposes. It allows businesses to store and analyze large volumes of structured and semi-structured data in a highly scalable and cost-effective manner. With Redshift, organizations can easily ingest, transform, and query their data, enabling them to gain valuable insights and make data-driven decisions. |
| Business Intelligence | Redshift is a popular choice for business intelligence (BI) applications. It provides fast query performance, allowing users to quickly generate reports, dashboards, and visualizations based on large datasets. Redshift’s columnar storage and parallel query execution make it efficient for processing complex analytical queries, enabling businesses to derive actionable insights from their data. |
| Log Analysis | Many companies utilize Redshift for log analysis. By loading log data into Redshift, organizations can easily analyze and monitor system logs, application logs, and website logs. Redshift’s scalability and performance help in processing and querying massive log datasets, enabling businesses to identify patterns, detect anomalies, and troubleshoot issues effectively. |
| Clickstream Analysis | Redshift is frequently employed for clickstream analysis, particularly in e-commerce and digital marketing domains. By storing and analyzing clickstream data in Redshift, organizations can gain insights into user behavior, website navigation patterns, and campaign performance. These insights can be used to optimize marketing strategies, improve user experience, and increase conversion rates. |
| Internet of Things (IoT) Analytics | Redshift is well-suited for analyzing data generated by IoT devices. With Redshift, businesses can ingest, store, and analyze large volumes of sensor data, telemetry data, and other IoT data streams. By leveraging Redshift’s scalability and computational power, organizations can uncover valuable insights from IoT data, enabling them to optimize operations, detect anomalies, and improve product performance. |
| Data Archiving | Redshift is often used for long-term data archiving. Organizations can offload historical data from their primary databases to Redshift, reducing the storage and maintenance costs associated with storing large volumes of data. Redshift’s columnar storage and compression capabilities help optimize storage efficiency, making it an ideal solution for cost-effective data archiving. |
| Machine Learning | Redshift can be integrated with machine learning frameworks and tools, allowing businesses to perform advanced analytics and predictive modeling on their data. By combining Redshift’s analytical capabilities with machine learning algorithms, organizations can build and deploy powerful predictive models for various applications, such as customer segmentation, fraud detection, and demand forecasting. |
| Real-Time Analytics | Redshift can be used to support real-time analytics scenarios. By continuously ingesting and processing streaming data using services like Amazon Kinesis, organizations can leverage Redshift to analyze and visualize real-time data streams. This enables businesses to make data-driven decisions in near real-time, leading to faster insights and improved operational efficiency. |
| Data Exploration and Discovery | Redshift enables users to explore and discover patterns, trends, and relationships in their data. With its fast query performance and support for complex analytical queries, Redshift allows users to perform ad-hoc analysis, conduct data mining, and uncover hidden insights. This empowers businesses to gain a deeper understanding of their data and make informed decisions based on actionable insights. |
TOP 10 AWS Redshift Related Technologies
Python
Python is one of the most popular programming languages for AWS Redshift software development. It is known for its simplicity, readability, and extensive library support, making it an ideal choice for data processing and analysis tasks.SQL
SQL (Structured Query Language) is a must-have skill for AWS Redshift software development. It is used to manage and manipulate data in Redshift databases efficiently. Knowledge of SQL is essential for writing optimized queries and performing data transformations.Amazon Redshift Query Editor
The Amazon Redshift Query Editor is a web-based tool that allows developers to write and execute SQL queries directly in the AWS Management Console. It provides a convenient interface for data exploration, query tuning, and performance optimization.AWS Glue
AWS Glue is a fully managed extract, transform, and load (ETL) service that makes it easy to prepare and load data for analytics on Redshift. It automatically generates ETL code and provides a visual interface for data mapping and transformation.Jupyter Notebook
Jupyter Notebook is a popular open-source web application that allows developers to create and share documents containing live code, visualizations, and explanatory text. It is commonly used for data analysis, exploration, and prototyping in AWS Redshift software development.AWS CloudFormation
AWS CloudFormation is a service that enables developers to create and manage AWS resources using declarative templates. It provides an efficient and scalable way to provision and configure Redshift clusters, making it an essential tool for infrastructure as code.AWS Lambda
AWS Lambda is a serverless computing service that allows developers to run code without provisioning or managing servers. It can be used to trigger automated data processing workflows, perform real-time data transformations, and integrate Redshift with other AWS services.
What are top AWS Redshift instruments and tools?
- AWS Redshift Query Editor: The AWS Redshift Query Editor is a web-based tool that allows users to run SQL queries directly from the AWS Management Console. It provides an intuitive interface with features such as syntax highlighting, auto-completion, and query history. It is widely used by data analysts and developers for ad-hoc querying and data exploration.
- AWS Redshift Spectrum: Redshift Spectrum is a feature of Amazon Redshift that enables querying data directly from files stored in Amazon S3, without the need to load the data into Redshift tables. It leverages the power of Redshift’s massively parallel processing capabilities to run queries on large-scale datasets stored in S3. This tool is particularly useful for analyzing data in a cost-effective and scalable manner.
- AWS Glue: AWS Glue is an Extract, Transform, Load (ETL) service that can be used in conjunction with Amazon Redshift to automate the process of preparing and loading data into Redshift. It provides a visual interface for creating and managing ETL jobs, making it easier to integrate and transform data from various sources into Redshift. AWS Glue also automatically generates the necessary code to execute the ETL jobs, saving time and effort for developers.
- AWS Data Pipeline: AWS Data Pipeline is a web service that enables users to orchestrate and automate the movement and transformation of data between different AWS services, including Amazon Redshift. It provides a visual interface for defining data workflows, allowing users to schedule and monitor the execution of data-driven tasks. With AWS Data Pipeline, users can easily create complex data processing pipelines involving Redshift and other AWS services.
- Snowflake: Snowflake is a cloud-based data warehousing platform that competes with Amazon Redshift. It offers similar functionalities to Redshift but with some key differences. Snowflake is known for its unique architecture that separates storage and compute, allowing users to scale each independently. It also provides built-in support for semi-structured data, such as JSON and Avro. Snowflake has gained popularity among data-driven organizations for its performance, scalability, and ease of use.
- Tableau: Tableau is a leading data visualization and business intelligence platform that can be integrated with Amazon Redshift. It allows users to connect to Redshift as a data source and create interactive dashboards and reports. Tableau provides a wide range of visualization options and advanced analytics capabilities, making it an ideal tool for exploring and communicating insights derived from Redshift data.
TOP 11 Facts about AWS Redshift
- AWS Redshift is a fully managed data warehousing service provided by Amazon Web Services (AWS).
- It is designed for analyzing large datasets and provides a fast, scalable, and cost-effective solution for data warehousing.
- Redshift uses columnar storage, which allows for efficient compression and faster query performance.
- It supports various data loading options, including bulk loading, streaming data, and data migration from other data sources.
- Redshift integrates seamlessly with other AWS services, such as S3 for data storage, AWS Glue for data cataloging, and AWS Lambda for event-driven computing.
- It offers automatic backups and replication to ensure data durability and high availability.
- Redshift provides advanced data security features, including encryption at rest and in transit, VPC security groups, and IAM roles for fine-grained access control.
- It supports a wide range of SQL-based analytics tools and business intelligence (BI) platforms for data analysis and visualization.
- Redshift Spectrum extends the capabilities of Redshift by allowing users to query data directly from S3 without the need for data movement or transformation.
- It offers on-demand pricing with no upfront costs and provides flexibility to scale compute and storage resources based on workload requirements.
- Redshift has a proven track record of serving large enterprises and startups alike, handling petabytes of data and supporting thousands of concurrent queries.
Talk to Our Expert
Our journey starts with a 30-min discovery call to explore your project challenges, technical needs and team diversity.

Yaroslav Kuntsevych
co-CEO