
'%3e%3cpath%20d='M0%2040.9959H9.00413V50H0V40.9959ZM0%2040.9959H9.00413V50H0V40.9959ZM0%2027.3306H9.00413V36.3348H0V27.3306ZM0%2013.6653H9.00413V22.6694H0V13.6653ZM0%200H9.00413V9.00408H0V0ZM13.2332%2040.9959H50V50H13.2332V40.9959ZM13.2332%2040.9959H50V50H13.2332V40.9959ZM13.2332%2027.3306H50V36.3348H13.2332V27.3306ZM13.2332%2013.6653H50V22.6694H13.2332V13.6653ZM13.2332%200H50V9.00408H13.2332V0Z'%20fill='%232049d8'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_2_8'%3e%3crect%20width='50'%20height='50'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)





Looking to hire RAG expert or build custom RAG application?
Table of Contents
- What is RAG (Retrieval Augmented Generation)?
- What is RAG AI (RAG Generative AI)?
- What is RAG in LLM (LLM Framework)?
- Graph RAG (Knowledge Graph RAG)
- RAG Developer Tech Stack
- RAG Architecture
- RAG Pipeline
- RAG Model
- RAG Quilt Patterns, RAG Doll Patterns
- RAG Application
- Benefits of Hiring RAG Developers from Upstaff
 RAG, a transformative approach in generative AI, integrates vector databases, knowledge graphs, and LLMs to produce responses that are not only coherent but also grounded in real-time, relevant data. Our developers have successfully delivered projects like semantic search platforms for e-commerce, automated customer support systems for SaaS companies, and specialized knowledge bases for legal and medical sectors. By hiring through Upstaff, you tap into a wealth of expertise in modern RAG architectures, pipelines, and tech stacks, ensuring your AI solutions reduce hallucination, improve response accuracy, and integrate seamlessly with existing systems. The benefits of RAG—such as enhanced precision, scalability, and adaptability—make it a game-changer for industries ranging from finance to healthcare. Choose Upstaff to hire RAG experts who can transform your vision into reality with innovative, reliable, and high-impact AI technology tailored to your unique needs.
RAG, a transformative approach in generative AI, integrates vector databases, knowledge graphs, and LLMs to produce responses that are not only coherent but also grounded in real-time, relevant data. Our developers have successfully delivered projects like semantic search platforms for e-commerce, automated customer support systems for SaaS companies, and specialized knowledge bases for legal and medical sectors. By hiring through Upstaff, you tap into a wealth of expertise in modern RAG architectures, pipelines, and tech stacks, ensuring your AI solutions reduce hallucination, improve response accuracy, and integrate seamlessly with existing systems. The benefits of RAG—such as enhanced precision, scalability, and adaptability—make it a game-changer for industries ranging from finance to healthcare. Choose Upstaff to hire RAG experts who can transform your vision into reality with innovative, reliable, and high-impact AI technology tailored to your unique needs.What is RAG (Retrieval Augmented Generation)?
Retrieval Augmented Generation (RAG) is a hybrid AI framework that revolutionizes how large language models operate by combining information retrieval with text generation. Unlike traditional LLMs that rely solely on static, pre-trained knowledge, RAG dynamically fetches relevant documents or data from external sources—such as vector databases like Pinecone, Weaviate, or FAISS—using advanced retrieval mechanisms like dense vector search. These retrieved documents are then fed into a generative model, such as GPT, Llama, or T5, to produce responses that are accurate, contextually relevant, and up-to-date. This approach is particularly powerful for applications requiring real-time or specialized knowledge, such as financial forecasting tools, academic research platforms, or customer support systems. RAG’s ability to ground responses in external data minimizes the risk of generating incorrect or outdated information, a common challenge with standalone LLMs. By integrating retrieval and generation, RAG enables businesses to build AI systems that are both intelligent and trustworthy, making it a cornerstone of modern AI innovation.What is RAG AI (RAG Generative AI)?
RAG AI, often referred to as RAG Generative AI, is the application of Retrieval Augmented Generation within the broader domain of generative artificial intelligence. It enhances the creative and linguistic capabilities of models like BERT, BART, or proprietary LLMs by augmenting them with external, factual data retrieved in real time. This ensures that the AI’s outputs are not only fluent and engaging but also precise and reliable, addressing the limitations of generative models that may produce plausible but incorrect responses (known as hallucination).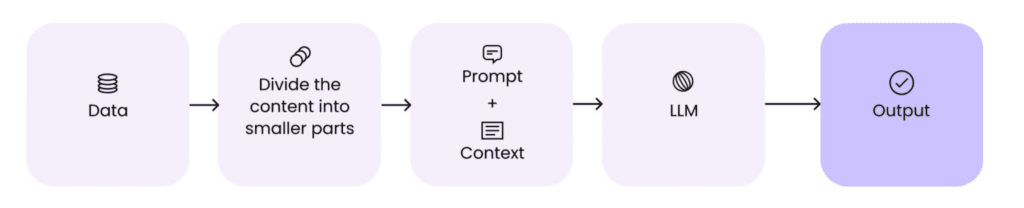 RAG is a system that processes at a large amount of data to finds the important pieces of content, and directs to a large language model (LLM) as context.
RAG use use cases like automated content creation, where it pulls from trusted sources to generate blog posts, or in conversational AI, where it retrieves product details to answer customer queries. Its versatility makes it a preferred choice for enterprises aiming to deploy AI that balances creativity with accuracy.
RAG is a system that processes at a large amount of data to finds the important pieces of content, and directs to a large language model (LLM) as context.
RAG use use cases like automated content creation, where it pulls from trusted sources to generate blog posts, or in conversational AI, where it retrieves product details to answer customer queries. Its versatility makes it a preferred choice for enterprises aiming to deploy AI that balances creativity with accuracy.
What is RAG in LLM (LLM Framework)?
Within the context of Large Language Models (LLMs), RAG serves as a powerful framework to address inherent limitations such as outdated knowledge, lack of domain-specific expertise, or propensity for generating unverified information. RAG in LLMs operates through a two-step process: first, a retriever module—typically powered by embedding models like Sentence-BERT or DPR (Dense Passage Retrieval)—identifies and fetches relevant documents from a knowledge base using techniques like cosine similarity over vector embeddings. Second, the retrieved data is passed to the LLM, which uses it as context to generate a response. This approach significantly enhances the LLM’s ability to handle complex, niche, or time-sensitive queries, such as retrieving the latest market trends for financial analysis or pulling case law for legal research. By grounding responses in external data, RAG reduces hallucination and boosts reliability, making it an essential component of modern LLM frameworks. For example, a RAG-powered LLM can answer questions about recent scientific discoveries by retrieving peer-reviewed papers, ensuring the response is both accurate and authoritative. Upstaff’s RAG developers are experts in implementing these frameworks, tailoring them to specific industries and use cases to maximize impact.Graph RAG (Knowledge Graph RAG)
Graph RAG, also known as Knowledge Graph RAG, is an advanced evolution of the RAG framework that leverages knowledge graphs—structured databases that represent entities and their relationships—to enhance retrieval precision. Unlike standard RAG, which retrieves unstructured text from vector databases, Graph RAG uses graph-based systems like Neo4j, Stardog, or RDF stores to fetch highly contextual, interconnected data. For instance, in a supply chain management system, Graph RAG can retrieve data about suppliers, products, and logistics relationships to answer complex queries like “Which suppliers can deliver component X within 48 hours?” This structured approach enables nuanced, relationship-driven responses, making it ideal for enterprise applications such as fraud detection, recommendation systems, or organizational knowledge management. Knowledge Graph RAG is particularly valuable in scenarios where understanding connections—such as social networks, biological pathways, or corporate hierarchies—is critical to delivering accurate insights. Upstaff’s RAG developers excel in building Graph RAG systems, ensuring your AI leverages the full power of structured data for superior performance.RAG Developer Tech Stack
A proficient RAG developer commands a robust and diverse tech stack to design, build, and optimize Retrieval Augmented Generation systems. Key technologies include:- Programming Languages: Python for AI development, JavaScript for front-end integration, and occasionally Go or Java for backend scalability.
- AI Frameworks and Libraries: Hugging Face Transformers for model fine-tuning, LangChain for chaining retrieval and generation, LlamaIndex for indexing, and PyTorch or TensorFlow for custom model development.
- Vector Databases: Pinecone, Weaviate, FAISS, or Milvus for efficient storage and retrieval of document embeddings.
- Knowledge Graph Technologies: Neo4j, Stardog, or SPARQL-based RDF stores for Graph RAG implementations.
- Cloud Platforms: AWS (SageMaker, RDS), Azure (Cognitive Search), or GCP (Vertex AI) for scalable deployment and model hosting.
- Search and Retrieval Tools: Elasticsearch for full-text search, Apache Solr for enterprise search, and REST/GraphQL APIs for integration.
- Orchestration and DevOps: Kubernetes for containerized deployments, Docker for environment consistency, and CI/CD pipelines for rapid iteration.
- Data Processing: Pandas, NumPy, and Spark for handling large datasets, and NLTK or spaCy for natural language processing.
RAG Architecture
The architecture of a RAG system is a modular, multi-layered design that integrates retrieval and generation seamlessly. At its core, it comprises two primary components: the retriever and the generator. The retriever, often powered by a transformer-based encoder like BERT or RoBERTa, converts input queries and documents into dense vector representations, enabling efficient similarity-based retrieval from a vector database. The generator, typically a transformer-based LLM like T5, BART, or a fine-tuned GPT variant, takes the retrieved documents and the query as input to produce a coherent, contextually accurate response. Supporting components include a vector database (e.g., Pinecone or FAISS) for storing document embeddings, middleware for preprocessing queries and post-processing outputs, and APIs (REST or GraphQL) for integrating the RAG system with front-end applications or external services. In advanced setups, the architecture may incorporate knowledge graphs for structured retrieval or caching layers for performance optimization. This flexible design allows RAG systems to scale across diverse use cases, from real-time chatbots to batch-processing analytics platforms. Upstaff’s RAG developers are adept at designing and implementing these architectures, ensuring robustness, scalability, and alignment with your project goals. RAG Comparison
RAG ComparisonRAG Pipeline
The RAG pipeline is a streamlined workflow that orchestrates the retrieval and generation processes to deliver accurate, context-aware responses. It consists of the following stages:- Query Encoding: The user’s query is transformed into a dense vector using an embedding model like Sentence-BERT or DPR, capturing its semantic meaning.
- Document Retrieval: The retriever searches a vector database or knowledge graph to identify documents or data snippets most relevant to the query, using metrics like cosine similarity or maximum inner product search.
- Context Augmentation: Retrieved documents are combined with the original query to form a rich contextual input, often formatted as a prompt for the LLM.
- Response Generation: The LLM processes the augmented paugmented input to generate a coherent and accurate response, leveraging the retrieved data to ensure accuracy.
- Post-Processing: The generated response undergoes refinement, such as removing redundancies, formatting for readability, or validating against additional sources for accuracy.
- Feedback Loop: User interactions or feedback are used to fine-tune the retriever or generator, improving performance over time.
RAG Model
A RAG model is the integrated system that combines a retriever and a generator to execute the RAG framework. Popular implementations include Hugging Face’s DPR (Dense Passage Retrieval) for the retriever, paired with generative models like T5, BART, or Llama. These models are often fine-tuned on domain-specific datasets to enhance retrieval accuracy and response relevance. For example, a RAG model for a medical application might be trained on PubMed articles and equipped with a specialized vector index to retrieve peer-reviewed studies. Advanced RAG models may incorporate ensemble methods, combining multiple retrievers or generators to improve performance, or leverage reinforcement learning to optimize response quality. Upstaff’s RAG developers are skilled in building and customizing these models, ensuring they meet the unique requirements of your project, whether it’s a real-time chatbot or a batch-processing analytics tool.RAG Quilt Patterns, RAG Doll Patterns
The terms “RAG quilt patterns” and “RAG doll patterns” occasionally appear in searches due to the shared acronym but are unrelated to Retrieval Augmented Generation. RAG quilt patterns refer to sewing designs that use frayed fabric edges to create textured, cozy quilts, popular in DIY crafting communities. Similarly, RAG doll patterns involve creating soft, handmade dolls with fabric scraps, often for decorative or sentimental purposes. At Upstaff, our focus is exclusively on RAG in the AI context—building sophisticated Retrieval Augmented Generation systems that power intelligent, data-driven applications. Our developers ensure clarity in delivering AI-focused RAG solutions, steering clear of any confusion with crafting patterns.RAG Application
RAG applications are transforming industries by enabling AI systems to deliver precise, context-aware solutions across diverse use cases. Here are some key examples:- Customer Support: RAG-powered chatbots retrieve company policies, product manuals, or FAQs to provide accurate, real-time answers, reducing response times and improving customer satisfaction.
- Healthcare: RAG systems pull from medical literature, clinical guidelines, or patient records to assist with diagnostics, treatment planning, or drug interaction checks, enhancing clinical decision-making.
- Legal: RAG tools retrieve case law, statutes, or regulatory documents to support legal research, contract analysis, or compliance monitoring, streamlining workflows for law firms.
- E-commerce: RAG enables personalized product recommendations by retrieving catalog data and user preferences, boosting conversion rates and customer engagement.
- Education: Intelligent tutoring systems use RAG to pull educational resources, such as textbooks or research papers, to provide tailored explanations or study guides.
- Finance: RAG systems retrieve market reports, financial regulations, or historical data to support investment analysis, risk assessment, or fraud detection.
- Media and Content Creation: RAG assists in generating articles, reports, or social media content by pulling from trusted sources, ensuring factual accuracy and relevance.
Benefits of Hiring RAG Developers from Upstaff
Choosing Upstaff to hire RAG developers means partnering with a team dedicated to delivering innovative, high-performance AI solutions. Our developers bring deep expertise in Retrieval Augmented Generation, from designing scalable RAG architectures to implementing Graph RAG systems for complex use cases. We ensure our talent is proficient in the latest tools, frameworks, and methodologies, enabling them to tackle projects of any scale or complexity. Whether you need a RAG-powered chatbot, a knowledge management system, or a custom AI application, Upstaff’s developers deliver solutions that enhance accuracy, reduce operational costs, and drive user satisfaction. Our rigorous vetting process guarantees you work with professionals who understand your industry and can align their technical skills with your business goals. Contact Upstaff today to hire RAG developers and unlock the transformative potential of generative AI for your organization.
Table of Contents
- What is RAG (Retrieval Augmented Generation)?
- What is RAG AI (RAG Generative AI)?
- What is RAG in LLM (LLM Framework)?
- Graph RAG (Knowledge Graph RAG)
- RAG Developer Tech Stack
- RAG Architecture
- RAG Pipeline
- RAG Model
- RAG Quilt Patterns, RAG Doll Patterns
- RAG Application
- Benefits of Hiring RAG Developers from Upstaff
Talk to Our Expert
Our journey starts with a 30-min discovery call to explore your project challenges, technical needs and team diversity.

Yaroslav Kuntsevych
co-CEO