

'%3e%3cpath%20d='M0%2040.9959H9.00413V50H0V40.9959ZM0%2040.9959H9.00413V50H0V40.9959ZM0%2027.3306H9.00413V36.3348H0V27.3306ZM0%2013.6653H9.00413V22.6694H0V13.6653ZM0%200H9.00413V9.00408H0V0ZM13.2332%2040.9959H50V50H13.2332V40.9959ZM13.2332%2040.9959H50V50H13.2332V40.9959ZM13.2332%2027.3306H50V36.3348H13.2332V27.3306ZM13.2332%2013.6653H50V22.6694H13.2332V13.6653ZM13.2332%200H50V9.00408H13.2332V0Z'%20fill='%232049d8'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_2_8'%3e%3crect%20width='50'%20height='50'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)







Want to hire Databricks developer? Then you should know!
The Databricks Data Intelligence Platform allows the entire organization to use data and AI. It’s built on a lakehouse to provide an open, unified foundation for all data and governance, and is powered by a Data Intelligence Engine that understands the uniqueness of your data.
The winners in every industry will be data and AI companies: from ETL to data warehousing to generative AI, Databricks helps simplify and accelerate data and AI goals.
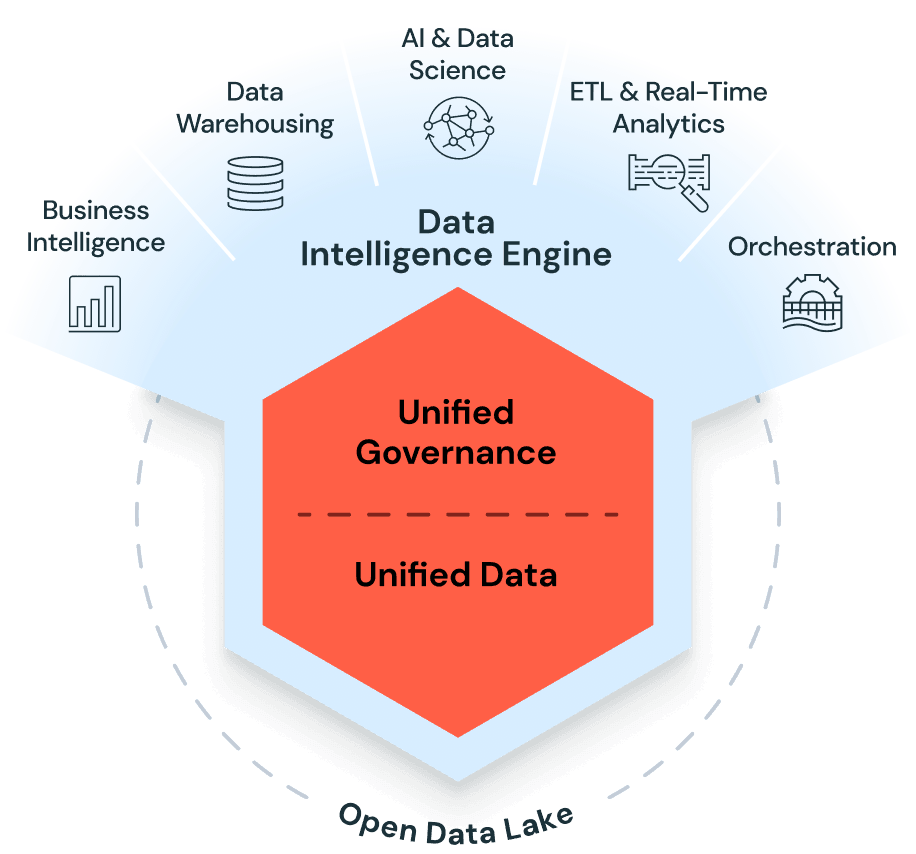
What are top Databricks instruments and tools?
- Databricks Runtime: Databricks Runtime is a cloud-based big data processing engine built on Apache Spark. It provides a unified analytics platform and optimized performance for running Apache Spark workloads. Databricks Runtime includes a preconfigured Spark environment with numerous optimizations and improvements, enabling faster and more efficient data processing.
- Databricks Delta: Databricks Delta is a unified data management system that combines data lake capabilities with data warehousing functionality. It provides ACID transactions, schema enforcement, and indexing, making it easier to build reliable and efficient data pipelines. Databricks Delta also enables fast query performance and efficient data storage, making it ideal for big data analytics and machine learning workloads.
- Databricks SQL Analytics: Databricks SQL Analytics is a collaborative SQL workspace that allows data analysts and data scientists to work with data using SQL queries. It provides a familiar SQL interface for exploring and analyzing data, with support for advanced analytics and machine learning. SQL Analytics integrates with other Databricks tools, enabling seamless collaboration and sharing of insights.
- Databricks MLflow: Databricks MLflow is an open-source platform for managing the machine learning lifecycle. It provides tools for tracking experiments, packaging and reproducibility, and model deployment. MLflow supports popular machine learning frameworks like TensorFlow, PyTorch, and scikit-learn, making it easier to develop and deploy machine learning models at scale.
- Databricks Connect: Databricks Connect allows users to connect their favorite integrated development environment (IDE) or notebook server to a Databricks workspace. It enables developers to write and test code locally while leveraging the power of Databricks clusters for distributed data processing. With Databricks Connect, users can seamlessly transition between local development and cluster execution.
- Databricks AutoML: Databricks AutoML is an automated machine learning framework that helps data scientists and analysts build accurate machine learning models with minimal effort. It automates the process of feature engineering, model selection, and hyperparameter tuning, making it easier to build high-performing models. Databricks AutoML leverages advanced techniques like genetic algorithms and Bayesian optimization to optimize model performance.
- Databricks Notebooks: Databricks Notebooks provide a collaborative environment for data exploration, analysis, and visualization. They support multiple programming languages, including Python, R, and Scala, and provide interactive capabilities for iterative data exploration. Databricks Notebooks also integrate with other Databricks tools, allowing seamless collaboration and sharing of notebooks.
TOP 14 Tech facts and history of creation and versions about Databricks Development
- Databricks was founded in 2013 by the creators of Apache Spark, a powerful open-source data processing engine.
- Apache Spark, developed at UC Berkeley’s AMPLab, served as the foundation for Databricks’ unified analytics platform.
- In 2014, Databricks launched its cloud-based platform, allowing users to leverage the power of Apache Spark without the complexities of infrastructure management.
- With its collaborative workspace, Databricks enables teams to work together on data projects, improving productivity and knowledge sharing.
- Databricks’ platform supports multiple programming languages, including Python, R, Scala, and SQL, providing flexibility for data scientists and engineers.
- In 2016, Databricks introduced Delta Lake, a transactional data management layer that brings reliability and scalability to data lakes.
- Databricks AutoML, launched in 2020, automates the machine learning pipeline, enabling data scientists to accelerate model development and deployment.
- Databricks’ MLflow, an open-source platform for managing machine learning lifecycles, was released in 2018, providing a seamless workflow for ML development.
- In 2020, Databricks announced the launch of SQL Analytics, a collaborative SQL workspace that allows data analysts to query data in real-time.
- Databricks Runtime, a pre-configured environment for running Spark applications, offers optimized performance and compatibility with various Spark versions.
- Databricks provides a unified data platform that integrates with popular data sources, such as Amazon S3, Azure Blob Storage, and Google Cloud Storage.
- With its Delta Engine, introduced in 2020, Databricks achieves high-performance query processing and significantly improves the speed of analytics workloads.
- Databricks has a strong presence in the cloud computing market, partnering with major cloud providers like AWS, Microsoft Azure, and Google Cloud Platform.
- Over the years, Databricks has gained traction among enterprises, empowering them to leverage big data and advanced analytics to drive innovation and insights.
- Databricks’ commitment to open-source collaboration has led to the growth of a vibrant community of developers contributing to the Apache Spark ecosystem.
TOP 10 Databricks Related Technologies
Python
Python is a widely-used programming language that is highly popular among data scientists and developers. It offers a simple syntax, extensive libraries, and excellent support for data manipulation and analysis. With Python, developers can easily integrate with Databricks and leverage its powerful features for data processing and machine learning.Apache Spark
Apache Spark is an open-source, distributed computing system that provides fast and scalable data processing capabilities. It is a core component of Databricks and enables developers to perform complex computations on large datasets. With its in-memory processing and fault-tolerance, Spark is ideal for handling big data workloads efficiently.Scala
Scala is a high-level programming language that runs on the Java Virtual Machine (JVM). It seamlessly integrates with Spark and Databricks, providing a concise and expressive syntax for building scalable and distributed applications. Scala’s functional programming capabilities and strong type system make it a preferred choice for many Databricks developers.R
R is a powerful language for statistical computing and graphics. It has a vast ecosystem of packages and libraries that are widely used in data analysis and machine learning. Databricks offers seamless integration with R, allowing developers to leverage its extensive capabilities for data exploration, visualization, and modeling.SQL
SQL (Structured Query Language) is the standard language for managing relational databases. Databricks provides a unified analytics platform that supports SQL queries, enabling developers to easily access and analyze data stored in various data sources. SQL is a fundamental skill for developers working with Databricks, as it allows efficient data manipulation and retrieval.AWS
Amazon Web Services (AWS) is a cloud computing platform that offers a wide range of services for building and deploying applications. Databricks can be seamlessly integrated with AWS, allowing developers to leverage its scalable infrastructure and services. By utilizing AWS with Databricks, developers can efficiently process, analyze, and store large volumes of data.Machine Learning
Machine learning is a subset of artificial intelligence that focuses on developing algorithms and models that can learn from and make predictions or decisions based on data. Databricks provides extensive support for machine learning tasks, offering libraries, tools, and frameworks such as TensorFlow and PyTorch. Developers can leverage these capabilities to build and deploy advanced machine learning models.
How and where is Databricks used?
| Case Name | Case Description |
|---|---|
| Data Exploration and Analysis | Databricks Development provides a powerful platform for data exploration and analysis. With its collaborative workspace, data scientists and analysts can easily perform complex queries, visualize data, and derive valuable insights. The platform supports various programming languages such as Python, R, and SQL, allowing users to leverage their preferred tools and libraries. By utilizing Databricks Development, organizations can efficiently explore and analyze large datasets, identify patterns, and make data-driven decisions. |
| Machine Learning and AI Development | Databricks Development enables seamless machine learning and AI development. Data scientists can leverage popular libraries like TensorFlow and PyTorch to build and train models on large datasets. The platform provides distributed computing capabilities, allowing for the efficient processing of complex algorithms. With Databricks Development, organizations can accelerate their AI initiatives, develop advanced models, and deploy them into production for real-world applications. |
| Real-time Streaming Analytics | Databricks Development is well-suited for real-time streaming analytics use cases. With its integration with Apache Kafka and other streaming frameworks, organizations can process and analyze data as it arrives, enabling real-time decision-making. The platform supports scalable and fault-tolerant streaming workflows, allowing businesses to derive insights from high-velocity data streams. Databricks Development empowers organizations to gain immediate insights from streaming data and take proactive actions based on real-time analytics. |
| Data Engineering and ETL | Databricks Development provides robust capabilities for data engineering and ETL (Extract, Transform, Load) tasks. With its scalable and distributed processing engine, users can efficiently transform and prepare data for downstream analysis. The platform integrates with popular data sources and tools, making it easy to ingest and process data from various systems. Databricks Development simplifies the complexities of data engineering, enabling organizations to build scalable and reliable data pipelines for their analytics and reporting needs. |
| Collaborative Data Science Projects | Databricks Development fosters collaboration among data scientists and analysts. The platform offers a shared workspace where multiple users can collaborate on data science projects simultaneously. Team members can share code, notebooks, and visualizations, facilitating knowledge sharing and improving productivity. Databricks Development enhances collaboration and enables cross-functional teams to work together seamlessly, accelerating the development and delivery of data-driven solutions. |
Talk to Our Expert
Our journey starts with a 30-min discovery call to explore your project challenges, technical needs and team diversity.

Yaroslav Kuntsevych
co-CEO